Benutzer Diskussion:TMg/characterSearch.js
aus Wikipedia, der freien encyclopedia
Dieses Benutzerskript analysiert den im normalen Suchfeld am oberen Bildschirmrand eingegebenen Text und zeigt die Unicode-Nummern (Codepunkte) und teilweise die Unicode-Namen der Schriftzeichen an. Das ist vor allem bei den zahlreichen verschiedenen Leerzeichen, Strichen und unsichtbaren Steuerzeichen nützlich, die sich ungewollt in Artikeltexte einschleichen können. Bemerkt man verdächtige Zeichen in einem Artikel, kann man diese markieren, mit Strg+C in die Zwischenablage kopieren und mit Strg+V ins Suchfeld einfügen. Um unsichtbare Zeichen zu analysieren, markiert man einfach etwas mehr rund um die verdächtige Stelle. Aus längeren Textabschnitten wählt das Skript automatisch die vermutlich problematischsten Zeichen aus und zeigt maximal zehn davon an.
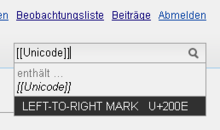
Das Skript entstand in Ergänzung zu meinem Auto-Formatter, der ungewollte Leer- und Steuerzeichen ebenfalls sichtbar macht und in eindeutigen Fällen automatisch entfernt.