Top Qs
Timeline
Chat
Perspective
Inverse transform sampling
Basic method for pseudo-random number sampling From Wikipedia, the free encyclopedia

Remove ads
Inverse transform sampling (also known as inversion sampling, the inverse probability integral transform, the inverse transformation method, or the Smirnov transform) is a basic method for pseudo-random number sampling, i.e., for generating sample numbers at random from any probability distribution given its cumulative distribution function.
Inverse transformation sampling takes uniform samples of a number between 0 and 1, interpreted as a probability, and then returns the smallest number such that for the cumulative distribution function of a random variable. For example, imagine that is the standard normal distribution with mean zero and standard deviation one. The table below shows samples taken from the uniform distribution and their representation on the standard normal distribution.



More information  ,
,  ...
...
 ,
,  ...
...We are randomly choosing a proportion of the area under the curve and returning the number in the domain such that exactly this proportion of the area occurs to the left of that number. Intuitively, we are unlikely to choose a number in the far end of tails because there is very little area in them which would require choosing a number very close to zero or one.
Computationally, this method involves computing the quantile function of the distribution — in other words, computing the cumulative distribution function (CDF) of the distribution (which maps a number in the domain to a probability between 0 and 1) and then inverting that function. This is the source of the term "inverse" or "inversion" in most of the names for this method. Note that for a discrete distribution, computing the CDF is not in general too difficult: we simply add up the individual probabilities for the various points of the distribution. For a continuous distribution, however, we need to integrate the probability density function (PDF) of the distribution, which is impossible to do analytically for most distributions (including the normal distribution). As a result, this method may be computationally inefficient for many distributions and other methods are preferred; however, it is a useful method for building more generally applicable samplers such as those based on rejection sampling.
For the normal distribution, the lack of an analytical expression for the corresponding quantile function means that other methods (e.g. the Box–Muller transform) may be preferred computationally. It is often the case that, even for simple distributions, the inverse transform sampling method can be improved on:[1] see, for example, the ziggurat algorithm and rejection sampling. On the other hand, it is possible to approximate the quantile function of the normal distribution extremely accurately using moderate-degree polynomials, and in fact the method of doing this is fast enough that inversion sampling is now the default method for sampling from a normal distribution in the statistical package R.[2]
Remove ads
Formal statement
For any random variable , the random variable has the same distribution as , where is the generalized inverse of the cumulative distribution function of and is uniform on .[3]






![{\displaystyle [0,1]}](http://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)
For continuous random variables, the inverse probability integral transform is indeed the inverse of the probability integral transform, which states that for a continuous random variable with cumulative distribution function , the random variable is uniform on .




Remove ads
Intuition
From , we want to generate with CDF We assume to be a continuous, strictly increasing function, which provides good intuition.
![{\displaystyle U\sim \mathrm {Unif} [0,1]}](http://wikimedia.org/api/rest_v1/media/math/render/svg/b6e22010588966c1d8492db40f1795db3a15aea9)


We want to see if we can find some strictly monotone transformation , such that . We will have
![{\displaystyle T:[0,1]\mapsto \mathbb {R} }](http://wikimedia.org/api/rest_v1/media/math/render/svg/957a365463e1db0539d89528f2f1d2e7c5e469d4)


where the last step used that when is uniform on .

So we got to be the inverse function of , or, equivalently

![{\displaystyle T(u)=F_{X}^{-1}(u),u\in [0,1].}](http://wikimedia.org/api/rest_v1/media/math/render/svg/bcd81ebf7a2ef3cbe8c03207df46fc559e6681c4)
Therefore, we can generate from

Remove ads
The method
Summarize
Perspective




The problem that the inverse transform sampling method solves is as follows:
- Let be a random variable whose distribution can be described by the cumulative distribution function .
- We want to generate values of which are distributed according to this distribution.
The inverse transform sampling method works as follows:
- Generate a random number from the standard uniform distribution in the interval , i.e. from
- Find the generalized inverse of the desired CDF, i.e. .
- Compute . The computed random variable has distribution and thereby the same law as .
![{\displaystyle U\sim \mathrm {Unif} [0,1].}](http://wikimedia.org/api/rest_v1/media/math/render/svg/a9e3cdfcf6e4924900b93b518404f5cc72450b08)



Expressed differently, given a cumulative distribution function and a uniform variable , the random variable has the distribution .[3]
![{\displaystyle U\in [0,1]}](http://wikimedia.org/api/rest_v1/media/math/render/svg/66966a6f68e58c668e96ae0c3d72967076188f6e)

In the continuous case, a treatment of such inverse functions as objects satisfying differential equations can be given.[4] Some such differential equations admit explicit power series solutions, despite their non-linearity.[5]
Remove ads
Examples
- As an example, suppose we have a random variable and a cumulative distribution function

- In order to perform an inversion we want to solve for
- From here we would perform steps one, two and three.



- As another example, we use the exponential distribution with for x ≥ 0 (and 0 otherwise). By solving y=F(x) we obtain the inverse function

- It means that if we draw some from a and compute This has exponential distribution.
- The idea is illustrated in the following graph:




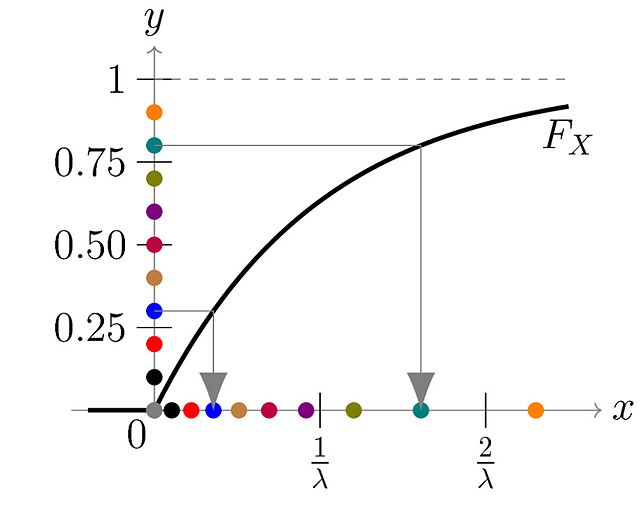
Random numbers yi are generated from a uniform distribution between 0 and 1, i.e. Y ~ U(0, 1). They are sketched as colored points on the y-axis. Each of the points is mapped according to x=F−1(y), which is shown with gray arrows for two example points. In this example, we have used an exponential distribution. Hence, for x ≥ 0, the probability density is and the cumulative distribution function is . Therefore, . We can see that using this method, many points end up close to 0 and only few points end up having high x-values - just as it is expected for an exponential distribution. - Note that the distribution does not change if we start with 1-y instead of y. For computational purposes, it therefore suffices to generate random numbers y in [0, 1] and then simply calculate





Remove ads
Proof of correctness
Summarize
Perspective
Let be a cumulative distribution function, and let be its generalized inverse function (using the infimum because CDFs are weakly monotonic and right-continuous):[6]


Claim: If is a uniform random variable on then has as its CDF.

Proof:
![{\displaystyle {\begin{aligned}&\Pr(F^{-1}(U)\leq x)\\&{}=\Pr(U\leq F(x))\quad &(F{\text{ is right-continuous, so }}\{u:F^{-1}(u)\leq x\}=\{u:u\leq F(x)\})\\&{}=F(x)\quad &({\text{because }}\Pr(U\leq u)=u,{\text{ when }}U{\text{ is uniform on }}[0,1])\\\end{aligned}}}](http://wikimedia.org/api/rest_v1/media/math/render/svg/98babd3462830f05cf280d73ee63039ac46e457a)
Remove ads
Truncated distribution
Inverse transform sampling can be simply extended to cases of truncated distributions on the interval without the cost of rejection sampling: the same algorithm can be followed, but instead of generating a random number uniformly distributed between 0 and 1, generate uniformly distributed between and , and then again take .
![{\displaystyle (a,b]}](http://wikimedia.org/api/rest_v1/media/math/render/svg/6a6969e731af335df071e247ee7fb331cd1a57ae)


Remove ads
Reduction of the number of inversions
In order to obtain a large number of samples, one needs to perform the same number of inversions of the distribution. One possible way to reduce the number of inversions while obtaining a large number of samples is the application of the so-called Stochastic Collocation Monte Carlo sampler (SCMC sampler) within a polynomial chaos expansion framework. This allows us to generate any number of Monte Carlo samples with only a few inversions of the original distribution with independent samples of a variable for which the inversions are analytically available, for example the standard normal variable.[7]
Remove ads
Software implementations
There are software implementations available for applying the inverse sampling method by using numerical approximations of the inverse in the case that it is not available in closed form. For example, an approximation of the inverse can be computed if the user provides some information about the distributions such as the PDF [8] or the CDF.
- C library UNU.RAN [9]
- R library Runuran [10]
- Python subpackage sampling in scipy.stats[11][12]
Remove ads
See also
- Probability integral transform
- Copula, defined by means of probability integral transform.
- Quantile function, for the explicit construction of inverse CDFs.
- Inverse distribution function for a precise mathematical definition for distributions with discrete components.
- Rejection sampling is another common technique to generate random variates that does not rely on inversion of the CDF.
References
Wikiwand - on
Seamless Wikipedia browsing. On steroids.
Remove ads