상위 질문
타임라인
채팅
관점
역변환 샘플링
위키백과, 무료 백과사전

Remove ads
역변환 샘플링(영어: Inverse transform sampling, 역샘플링(inversion sampling), 역확률 적분 변환(inverse probability integral transform), 역변환 방법(inverse transformation method) 또는 스미르노프 변환(Smirnov transform)으로도 알려져 있음)은 유사난수 샘플링, 즉 주어진 누적 분포 함수를 갖는 모든 확률 분포에서 무작위로 샘플 번호를 생성하기 위한 기본적인 방법이다.
역변환 샘플링은 0에서 1 사이의 숫자 의 균등 샘플을 확률로 해석하고, 그 다음 확률 변수의 누적 분포 함수 에 대해 인 가장 작은 숫자 를 반환한다. 예를 들어, 가 평균이 0이고 표준 편차가 1인 표준 정규 분포라고 상상해 보자. 아래 표는 균등 분포에서 추출한 샘플과 표준 정규 분포에서의 그 표현을 보여준다.



자세한 정보  ,
,  ...
...
 ,
,  ...
...
우리는 곡선 아래 면적의 비율을 무작위로 선택하고, 해당 숫자의 왼쪽에 정확히 이 비율의 면적이 나타나도록 도메인의 숫자를 반환한다. 직관적으로, 꼬리의 먼 끝 부분에는 면적이 매우 적기 때문에 해당 부분의 숫자를 선택할 가능성은 낮다. 이는 0 또는 1에 매우 가까운 숫자를 선택해야 함을 의미한다.
계산적으로 이 방법은 분포의 분위수함수를 계산하는 것을 포함한다. 즉, 분포의 누적 분포 함수(CDF)를 계산하고(도메인의 숫자를 0에서 1 사이의 확률에 매핑함) 그 함수를 반전시키는 것이다. 이것이 이 방법의 대부분의 이름에 "역" 또는 "반전"이라는 용어가 붙는 이유이다. 이산 분포의 경우 CDF를 계산하는 것은 일반적으로 너무 어렵지 않다. 분포의 다양한 점에 대한 개별 확률을 단순히 합산하면 된다. 그러나 연속 분포의 경우 분포의 확률 밀도 함수(PDF)를 통합해야 하는데, 이는 대부분의 분포(정규 분포 포함)에 대해 분석적으로 수행하는 것이 불가능하다. 결과적으로 이 방법은 많은 분포에 대해 계산적으로 비효율적일 수 있으며 다른 방법이 선호된다. 그러나 채택기각법을 기반으로 하는 것과 같이 더 일반적으로 적용 가능한 샘플러를 구축하는 데 유용한 방법이다.
정규 분포의 경우 해당 분위수 함수에 대한 해석적 표현이 없으므로 다른 방법(예: 박스-뮬러 변환)이 계산적으로 선호될 수 있다. 심지어 간단한 분포의 경우에도 역변환 샘플링 방법을 개선할 수 있는 경우가 많다.[1] 예를 들어, 지구라트 알고리즘 및 채택기각법을 참조하라. 반면에, 정규 분포의 분위수 함수를 중간 정도의 다항식을 사용하여 매우 정확하게 근사할 수 있으며, 실제로 이 방법을 사용하는 것이 충분히 빨라 R 통계 패키지에서 정규 분포에서 샘플링하는 기본 방법이 되었다.[2]
Remove ads
형식적 진술
어떤 확률 변수 에 대해서도, 확률 변수 는 와 같은 분포를 가지며, 여기서 는 의 일반화된 역함수이고 는 에서 균일하다.[3]





![{\displaystyle [0,1]}](http://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)
연속 확률 변수의 경우, 역확률 적분 변환은 실제로 확률 적분 변환의 역함수이며, 이는 누적 분포 함수 를 갖는 연속 확률 변수 에 대해 확률 변수 가 에서 균일하다는 것을 나타낸다.





Remove ads
직관
에서, 우리는 CDF 를 갖는 를 생성하려고 한다. 우리는 를 연속적이고 엄격하게 증가하는 함수라고 가정하며, 이는 좋은 직관을 제공한다.
![{\displaystyle U\sim \mathrm {Unif} [0,1]}](http://wikimedia.org/api/rest_v1/media/math/render/svg/b6e22010588966c1d8492db40f1795db3a15aea9)

우리는 가 되도록 엄격하게 단조로운 변환 을 찾을 수 있는지 확인하고자 한다. 우리는 다음을 갖게 될 것이다.

![{\displaystyle T:[0,1]\mapsto \mathbb {R} }](http://wikimedia.org/api/rest_v1/media/math/render/svg/957a365463e1db0539d89528f2f1d2e7c5e469d4)

여기서 마지막 단계는 가 에서 균일할 때 라는 것을 사용했다.

그래서 우리는 가 의 역함수가 되도록 얻었다. 또는 동등하게

![{\displaystyle T(u)=F_{X}^{-1}(u),u\in [0,1].}](http://wikimedia.org/api/rest_v1/media/math/render/svg/bcd81ebf7a2ef3cbe8c03207df46fc559e6681c4)
따라서 로부터 를 생성할 수 있다.
Remove ads
방법
요약
관점




역변환 샘플링 방법이 해결하는 문제는 다음과 같다.
역변환 샘플링 방법은 다음과 같이 작동한다.
- 표준 균등 분포 에서 난수 를 생성한다. 즉, 에서.
- 원하는 CDF의 일반화된 역함수를 찾는다. 즉, .
- 를 계산한다. 계산된 확률 변수 는 분포를 가지며 따라서 와 동일한 법칙을 따른다.
![{\displaystyle U\sim \mathrm {Unif} [0,1].}](http://wikimedia.org/api/rest_v1/media/math/render/svg/a9e3cdfcf6e4924900b93b518404f5cc72450b08)



다르게 표현하면, 누적 분포 함수 와 균등 변수 가 주어졌을 때, 확률 변수 는 분포 를 갖는다.[3]
![{\displaystyle U\in [0,1]}](http://wikimedia.org/api/rest_v1/media/math/render/svg/66966a6f68e58c668e96ae0c3d72967076188f6e)

연속적인 경우, 이러한 역함수를 미분 방정식을 만족하는 객체로 취급할 수 있다.[4] 이러한 미분 방정식 중 일부는 비선형성에도 불구하고 명시적인 멱급수 해를 허용한다.[5]
Remove ads
예시
- 예를 들어, 인 확률 변수와 다음 누적 분포 함수가 있다고 가정하자.

- 역변환을 수행하기 위해 를 풀고자 한다.
- 여기에서 1단계, 2단계, 3단계를 수행한다.



- 다른 예로, x ≥ 0 (그 외에는 0)에 대해 인 지수 분포를 사용한다. y=F(x)를 풀면 역함수를 얻는다.

- 이는 에서 를 뽑고 를 계산하면, 이 는 지수 분포를 따른다는 의미이다.
- 이 아이디어는 다음 그래프에 설명되어 있다.




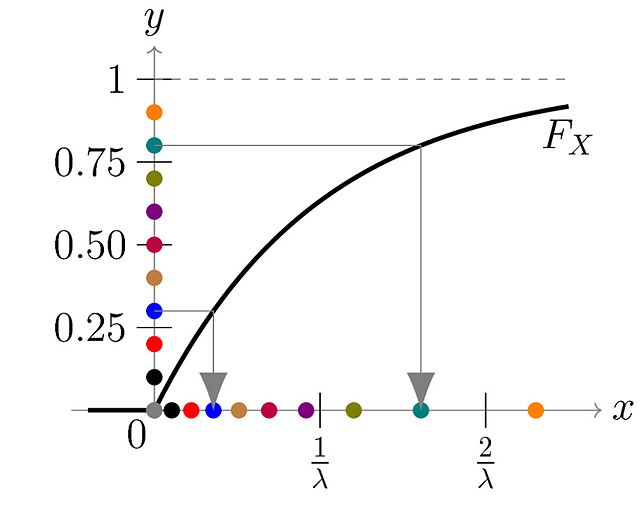
난수 yi는 0과 1 사이의 균등 분포, 즉 Y ~ U(0, 1)에서 생성된다. 이들은 y축에 색깔 있는 점으로 표시된다. 각 점은 x=F−1(y)에 따라 매핑되며, 두 예시 점에 대해 회색 화살표로 표시된다. 이 예에서는 지수 분포를 사용했다. 따라서 x ≥ 0에 대해 확률 밀도는 이고 누적 분포 함수는 이다. 그러므로 이다. 이 방법을 사용하면 많은 점이 0에 가깝게 끝나고, 지수 분포에서 예상되는 바와 같이 높은 x 값을 갖는 점은 소수에 불과하다. - y 대신 1-y로 시작해도 분포는 변하지 않는다는 점에 유의하라. 따라서 계산 목적으로는 [0, 1]에서 난수 y를 생성한 다음 단순히 다음을 계산하는 것으로 충분하다.





Remove ads
정확성 증명
요약
관점
가 누적 분포 함수이고, 가 그 일반화된 역함수라고 하자(CDFS는 약한 단조 함수이고 오른쪽 연속 함수이므로 하한을 사용한다).[6]


주장: 가 상의 균등 확률 변수이면 는 를 CDF로 가진다.

증명:
![{\displaystyle {\begin{aligned}&\Pr(F^{-1}(U)\leq x)\\&{}=\Pr(U\leq F(x))\quad &(F{\text{ is right-continuous, so }}\{u:F^{-1}(u)\leq x\}=\{u:u\leq F(x)\})\\&{}=F(x)\quad &({\text{because }}\Pr(U\leq u)=u,{\text{ when }}U{\text{ is uniform on }}[0,1])\\\end{aligned}}}](http://wikimedia.org/api/rest_v1/media/math/render/svg/98babd3462830f05cf280d73ee63039ac46e457a)
Remove ads
절단된 분포
역변환 샘플링은 구간 에서 절단된 분포의 경우에도 채택기각법의 비용 없이 간단하게 확장될 수 있다. 동일한 알고리즘을 따를 수 있지만, 0과 1 사이에서 균일하게 분포된 난수 를 생성하는 대신 와 사이에서 균일하게 분포된 를 생성한 다음 다시 를 취한다.
![{\displaystyle (a,b]}](http://wikimedia.org/api/rest_v1/media/math/render/svg/6a6969e731af335df071e247ee7fb331cd1a57ae)


Remove ads
역변환 횟수 감소
많은 수의 샘플을 얻으려면 분포의 역변환을 같은 횟수로 수행해야 한다. 많은 수의 샘플을 얻으면서 역변환 횟수를 줄이는 한 가지 방법은 다항 카오스 확장 프레임워크 내에서 소위 확률적 콜로케이션 몬테카를로 샘플러(SCMC 샘플러)를 적용하는 것이다. 이를 통해 예를 들어 표준 정규 변수와 같이 역변환을 분석적으로 사용할 수 있는 변수의 독립 샘플을 사용하여 원본 분포의 몇 가지 역변환만으로 모든 수의 몬테카를로 샘플을 생성할 수 있다.[7]
소프트웨어 구현
역변환이 닫힌 형식으로 제공되지 않는 경우 역함수의 수치적 근사를 사용하여 역변환 샘플링 방법을 적용할 수 있는 소프트웨어 구현이 제공된다. 예를 들어, 사용자가 PDF[8] 또는 CDF와 같은 분포에 대한 일부 정보를 제공하는 경우 역함수의 근사를 계산할 수 있다.
- C 라이브러리 UNU.RAN[9]
- R 라이브러리 Runuran[10]
- scipy.stats의 Python 서브패키지 샘플링[11][12]
같이 보기
- 확률 적분 변환
- 코퓰라: 확률 적분 변환을 통해 정의
- 분위수함수: 역 CDF의 명시적 구성을 위해
- 누적 분포 함수#역 분포 함수 (분위수 함수): 이산 구성 요소를 가진 분포에 대한 정확한 수학적 정의
- 채택기각법: CDF의 역변환에 의존하지 않는 또 다른 일반적인 무작위 변량 생성 기술
각주
Wikiwand - on
Seamless Wikipedia browsing. On steroids.
Remove ads