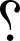Punctuation marks in Unicode |
|---|
| Mark |
Name |
Code point |
General Category |
Script |
| Pd, dash |
| - |
HYPHEN-MINUS |
U+002D |
Pd, dash |
Common |
| ‐ |
HYPHEN |
U+2010 |
Pd, dash |
Common |
| ‑ |
NON-BREAKING HYPHEN |
U+2011 |
Pd, dash |
Common |
| ‒ |
FIGURE DASH |
U+2012 |
Pd, dash |
Common |
| – |
EN DASH |
U+2013 |
Pd, dash |
Common |
| — |
EM DASH |
U+2014 |
Pd, dash |
Common |
| ― |
HORIZONTAL BAR |
U+2015 |
Pd, dash |
Common |
| ⸗ |
DOUBLE OBLIQUE HYPHEN |
U+2E17 |
Pd, dash |
Common |
| ⸚ |
HYPHEN WITH DIAERESIS |
U+2E1A |
Pd, dash |
Common |
| ⸺ |
TWO-EM DASH |
U+2E3A |
Pd, dash |
Common |
| ⸻ |
THREE-EM DASH |
U+2E3B |
Pd, dash |
Common |
| ⹀ |
DOUBLE HYPHEN |
U+2E40 |
Pd, dash |
Common |
| 〜 |
WAVE DASH |
U+301C |
Pd, dash |
Common |
| 〰 |
WAVY DASH |
U+3030 |
Pd, dash |
Common |
| ゠ |
KATAKANA-HIRAGANA DOUBLE HYPHEN |
U+30A0 |
Pd, dash |
Common |
| ︱ |
PRESENTATION FORM FOR VERTICAL EM DASH |
U+FE31 |
Pd, dash |
Common |
| ︲ |
PRESENTATION FORM FOR VERTICAL EN DASH |
U+FE32 |
Pd, dash |
Common |
| ﹘ |
SMALL EM DASH |
U+FE58 |
Pd, dash |
Common |
| ﹣ |
SMALL HYPHEN-MINUS |
U+FE63 |
Pd, dash |
Common |
| - |
FULLWIDTH HYPHEN-MINUS |
U+FF0D |
Pd, dash |
Common |
| ֊ |
ARMENIAN HYPHEN |
U+058A |
Pd, dash |
Armenian |
| ᐀ |
CANADIAN SYLLABICS HYPHEN |
U+1400 |
Pd, dash |
Canadian Aboriginal |
| ־ |
HEBREW PUNCTUATION MAQAF |
U+05BE |
Pd, dash |
Hebrew |
| ᠆ |
MONGOLIAN TODO SOFT HYPHEN |
U+1806 |
Pd, dash |
Mongolian |
| 𐺭 |
YEZIDI HYPHENATION MARK |
U+10EAD |
Pd, dash |
Yezidi |
| Pi-Pf, initial–final quote |
| « » |
- LEFT-POINTING DOUBLE ANGLE QUOTATION MARK
- RIGHT-POINTING DOUBLE ANGLE QUOTATION MARK
|
|
|
Common |
| ‘ ’ |
- LEFT SINGLE QUOTATION MARK
- RIGHT SINGLE QUOTATION MARK
|
|
|
Common |
| ‛ |
SINGLE HIGH-REVERSED-9 QUOTATION MARK |
U+201B |
Pi, initial quote |
Common |
| “ ” |
- LEFT DOUBLE QUOTATION MARK
- RIGHT DOUBLE QUOTATION MARK
|
|
|
Common |
| ‟ |
DOUBLE HIGH-REVERSED-9 QUOTATION MARK |
U+201F |
Pi, initial quote |
Common |
| ‹ › |
- SINGLE LEFT-POINTING ANGLE QUOTATION MARK
- SINGLE RIGHT-POINTING ANGLE QUOTATION MARK
|
|
|
Common |
| ⸂ ⸃ |
- LEFT SUBSTITUTION BRACKET
- RIGHT SUBSTITUTION BRACKET
|
|
|
Common |
| ⸄ ⸅ |
- LEFT DOTTED SUBSTITUTION BRACKET
- RIGHT DOTTED SUBSTITUTION BRACKET
|
|
|
Common |
| ⸉ ⸊ |
- LEFT TRANSPOSITION BRACKET
- RIGHT TRANSPOSITION BRACKET
|
|
|
Common |
| ⸌ ⸍ |
- LEFT RAISED OMISSION BRACKET
- RIGHT RAISED OMISSION BRACKET
|
|
|
Common |
| ⸜ ⸝ |
- LEFT LOW PARAPHRASE BRACKET
- RIGHT LOW PARAPHRASE BRACKET
|
|
|
Common |
| ⸠ ⸡ |
- LEFT VERTICAL BAR WITH QUILL
- RIGHT VERTICAL BAR WITH QUILL
|
|
|
Common |
| Ps-Pe, open–close (brackets) |
| ( ) |
- LEFT PARENTHESIS
- RIGHT PARENTHESIS
|
|
|
Common |
| [ ] |
- LEFT SQUARE BRACKET
- RIGHT SQUARE BRACKET
|
|
|
Common |
| { } |
- LEFT CURLY BRACKET
- RIGHT CURLY BRACKET
|
|
|
Common |
| ‚ |
SINGLE LOW-9 QUOTATION MARK |
U+201A |
Ps, open |
Common |
| „ |
DOUBLE LOW-9 QUOTATION MARK |
U+201E |
Ps, open |
Common |
| ⁅ ⁆ |
- LEFT SQUARE BRACKET WITH QUILL
- RIGHT SQUARE BRACKET WITH QUILL
|
|
|
Common |
| ⁽ ⁾ |
- SUPERSCRIPT LEFT PARENTHESIS
- SUPERSCRIPT RIGHT PARENTHESIS
|
|
|
Common |
| ₍ ₎ |
- SUBSCRIPT LEFT PARENTHESIS
- SUBSCRIPT RIGHT PARENTHESIS
|
|
|
Common |
| ⌈ ⌉ |
- LEFT CEILING
- RIGHT CEILING
|
|
|
Common |
| ⌊ ⌋ |
|
|
|
Common |
| 〈 〉 |
- LEFT-POINTING ANGLE BRACKET
- RIGHT-POINTING ANGLE BRACKET
|
|
|
Common |
| ❨ ❩ |
- MEDIUM LEFT PARENTHESIS ORNAMENT
- MEDIUM RIGHT PARENTHESIS ORNAMENT
|
|
|
Common |
| ❪ ❫ |
- MEDIUM FLATTENED LEFT PARENTHESIS ORNAMENT
- MEDIUM FLATTENED RIGHT PARENTHESIS ORNAMENT
|
|
|
Common |
| ❬ ❭ |
- MEDIUM LEFT-POINTING ANGLE BRACKET ORNAMENT
- MEDIUM RIGHT-POINTING ANGLE BRACKET ORNAMENT
|
|
|
Common |
| ❮ ❯ |
- HEAVY LEFT-POINTING ANGLE QUOTATION MARK ORNAMENT
- HEAVY RIGHT-POINTING ANGLE QUOTATION MARK ORNAMENT
|
|
|
Common |
| ❰ ❱ |
- HEAVY LEFT-POINTING ANGLE BRACKET ORNAMENT
- HEAVY RIGHT-POINTING ANGLE BRACKET ORNAMENT
|
|
|
Common |
| ❲ ❳ |
- LIGHT LEFT TORTOISE SHELL BRACKET ORNAMENT
- LIGHT RIGHT TORTOISE SHELL BRACKET ORNAMENT
|
|
|
Common |
| ❴ ❵ |
- MEDIUM LEFT CURLY BRACKET ORNAMENT
- MEDIUM RIGHT CURLY BRACKET ORNAMENT
|
|
|
Common |
| ⟅ ⟆ |
- LEFT S-SHAPED BAG DELIMITER
- RIGHT S-SHAPED BAG DELIMITER
|
|
|
Common |
| ⟦ ⟧ |
- MATHEMATICAL LEFT WHITE SQUARE BRACKET
- MATHEMATICAL RIGHT WHITE SQUARE BRACKET
|
|
|
Common |
| ⟨ ⟩ |
- MATHEMATICAL LEFT ANGLE BRACKET
- MATHEMATICAL RIGHT ANGLE BRACKET
|
|
|
Common |
| ⟪ ⟫ |
- MATHEMATICAL LEFT DOUBLE ANGLE BRACKET
- MATHEMATICAL RIGHT DOUBLE ANGLE BRACKET
|
|
|
Common |
| ⟬ ⟭ |
- MATHEMATICAL LEFT WHITE TORTOISE SHELL BRACKET
- MATHEMATICAL RIGHT WHITE TORTOISE SHELL BRACKET
|
|
|
Common |
| ⟮ ⟯ |
- MATHEMATICAL LEFT FLATTENED PARENTHESIS
- MATHEMATICAL RIGHT FLATTENED PARENTHESIS
|
|
|
Common |
| ⦃ ⦄ |
- LEFT WHITE CURLY BRACKET
- RIGHT WHITE CURLY BRACKET
|
|
|
Common |
| ⦅ ⦆ |
- LEFT WHITE PARENTHESIS
- RIGHT WHITE PARENTHESIS
|
|
|
Common |
| ⦇ ⦈ |
- Z NOTATION LEFT IMAGE BRACKET
- Z NOTATION RIGHT IMAGE BRACKET
|
|
|
Common |
| ⦉ ⦊ |
- Z NOTATION LEFT BINDING BRACKET
- Z NOTATION RIGHT BINDING BRACKET
|
|
|
Common |
| ⦋ ⦌ |
- LEFT SQUARE BRACKET WITH UNDERBAR
- RIGHT SQUARE BRACKET WITH UNDERBAR
|
|
|
Common |
| ⦍ ⦎ |
- LEFT SQUARE BRACKET WITH TICK IN TOP CORNER
- RIGHT SQUARE BRACKET WITH TICK IN BOTTOM CORNER
|
|
|
Common |
| ⦏ ⦐ |
- LEFT SQUARE BRACKET WITH TICK IN BOTTOM CORNER
- RIGHT SQUARE BRACKET WITH TICK IN TOP CORNER
|
|
|
Common |
| ⦑ ⦒ |
- LEFT ANGLE BRACKET WITH DOT
- RIGHT ANGLE BRACKET WITH DOT
|
|
|
Common |
| ⦓ ⦔ |
- LEFT ARC LESS-THAN BRACKET
- RIGHT ARC GREATER-THAN BRACKET
|
|
|
Common |
| ⦕ ⦖ |
- DOUBLE LEFT ARC GREATER-THAN BRACKET
- DOUBLE RIGHT ARC LESS-THAN BRACKET
|
|
|
Common |
| ⦗ ⦘ |
- LEFT BLACK TORTOISE SHELL BRACKET
- RIGHT BLACK TORTOISE SHELL BRACKET
|
|
|
Common |
| ⧘ ⧙ |
- LEFT WIGGLY FENCE
- RIGHT WIGGLY FENCE
|
|
|
Common |
| ⧚ ⧛ |
- LEFT DOUBLE WIGGLY FENCE
- RIGHT DOUBLE WIGGLY FENCE
|
|
|
Common |
| ⧼ ⧽ |
- LEFT-POINTING CURVED ANGLE BRACKET
- RIGHT-POINTING CURVED ANGLE BRACKET
|
|
|
Common |
| ⸢ ⸣ |
- TOP LEFT HALF BRACKET
- TOP RIGHT HALF BRACKET
|
|
|
Common |
| ⸤ ⸥ |
- BOTTOM LEFT HALF BRACKET
- BOTTOM RIGHT HALF BRACKET
|
|
|
Common |
| ⸦ ⸧ |
- LEFT SIDEWAYS U BRACKET
- RIGHT SIDEWAYS U BRACKET
|
|
|
Common |
| ⸨ ⸩ |
- LEFT DOUBLE PARENTHESIS
- RIGHT DOUBLE PARENTHESIS
|
|
|
Common |
| ⹂ |
DOUBLE LOW-REVERSED-9 QUOTATION MARK |
U+2E42 |
Ps, open |
Common |
| 〈 〉 |
- LEFT ANGLE BRACKET
- RIGHT ANGLE BRACKET
|
|
|
Common |
| 《 》 |
- LEFT DOUBLE ANGLE BRACKET
- RIGHT DOUBLE ANGLE BRACKET
|
|
|
Common |
| 「 」 |
- LEFT CORNER BRACKET
- RIGHT CORNER BRACKET
|
|
|
Common |
| 『 』 |
- LEFT WHITE CORNER BRACKET
- RIGHT WHITE CORNER BRACKET
|
|
|
Common |
| 【 】 |
- LEFT BLACK LENTICULAR BRACKET
- RIGHT BLACK LENTICULAR BRACKET
|
|
|
Common |
| 〔 〕 |
- LEFT TORTOISE SHELL BRACKET
- RIGHT TORTOISE SHELL BRACKET
|
|
|
Common |
| 〖 〗 |
- LEFT WHITE LENTICULAR BRACKET
- RIGHT WHITE LENTICULAR BRACKET
|
|
|
Common |
| 〘 〙 |
- LEFT WHITE TORTOISE SHELL BRACKET
- RIGHT WHITE TORTOISE SHELL BRACKET
|
|
|
Common |
| 〚 〛 |
- LEFT WHITE SQUARE BRACKET
- RIGHT WHITE SQUARE BRACKET
|
|
|
Common |
| 〝 〞 |
- REVERSED DOUBLE PRIME QUOTATION MARK
- DOUBLE PRIME QUOTATION MARK
|
|
|
Common |
| 〟 |
LOW DOUBLE PRIME QUOTATION MARK |
U+301F |
Pe, close |
Common |
| ﴿ |
ORNATE RIGHT PARENTHESIS |
U+FD3F |
Ps, open |
Common |
| ︗ ︘ |
- PRESENTATION FORM FOR VERTICAL LEFT WHITE LENTICULAR BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT WHITE LENTICULAR BRAKCET
|
|
|
Common |
| ︵ ︶ |
- PRESENTATION FORM FOR VERTICAL LEFT PARENTHESIS
- PRESENTATION FORM FOR VERTICAL RIGHT PARENTHESIS
|
|
|
Common |
| ︷ ︸ |
- PRESENTATION FORM FOR VERTICAL LEFT CURLY BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT CURLY BRACKET
|
|
|
Common |
| ︹ ︺ |
- PRESENTATION FORM FOR VERTICAL LEFT TORTOISE SHELL BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT TORTOISE SHELL BRACKET
|
|
|
Common |
| ︻ ︼ |
- PRESENTATION FORM FOR VERTICAL LEFT BLACK LENTICULAR BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT BLACK LENTICULAR BRACKET
|
|
|
Common |
| ︽ ︾ |
- PRESENTATION FORM FOR VERTICAL LEFT DOUBLE ANGLE BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT DOUBLE ANGLE BRACKET
|
|
|
Common |
| ︿ ﹀ |
- PRESENTATION FORM FOR VERTICAL LEFT ANGLE BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT ANGLE BRACKET
|
|
|
Common |
| ﹁ ﹂ |
- PRESENTATION FORM FOR VERTICAL LEFT CORNER BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT CORNER BRACKET
|
|
|
Common |
| ﹃ ﹄ |
- PRESENTATION FORM FOR VERTICAL LEFT WHITE CORNER BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT WHITE CORNER BRACKET
|
|
|
Common |
| ﹇ ﹈ |
- PRESENTATION FORM FOR VERTICAL LEFT SQUARE BRACKET
- PRESENTATION FORM FOR VERTICAL RIGHT SQUARE BRACKET
|
|
|
Common |
| ﹙ ﹚ |
- SMALL LEFT PARENTHESIS
- SMALL RIGHT PARENTHESIS
|
|
|
Common |
| ﹛ ﹜ |
- SMALL LEFT CURLY BRACKET
- SMALL RIGHT CURLY BRACKET
|
|
|
Common |
| ﹝ ﹞ |
- SMALL LEFT TORTOISE SHELL BRACKET
- SMALL RIGHT TORTOISE SHELL BRACKET
|
|
|
Common |
| ( ) |
- FULLWIDTH LEFT PARENTHESIS
- FULLWIDTH RIGHT PARENTHESIS
|
|
|
Common |
| [ ] |
- FULLWIDTH LEFT SQUARE BRACKET
- FULLWIDTH RIGHT SQUARE BRACKET
|
|
|
Common |
| { } |
- FULLWIDTH LEFT CURLY BRACKET
- FULLWIDTH RIGHT CURLY BRACKET
|
|
|
Common |
| ⦅ ⦆ |
- FULLWIDTH LEFT WHITE PARENTHESIS
- FULLWIDTH RIGHT WHITE PARENTHESIS
|
|
|
Common |
| 「 」 |
- HALFWIDTH LEFT CORNER BRACKET
- HALFWIDTH RIGHT CORNER BRACKET
|
|
|
Common |
| ᚛ ᚜ |
- OGHAM FEATHER MARK
- OGHAM REVERSED FEATHER MARK
|
|
|
Ogham |
| ༺ ༻ |
- TIBETAN MARK GUG RTAGS GYON
- TIBETAN MARK GUG RTAGS GYAS
|
|
|
Tibetan |
| ༼ ༽ |
- TIBETAN MARK ANG KHANG GYON
- TIBETAN MARK ANG KHANG GYAS
|
|
|
Tibetan |
| Pc, connector |
| _ |
LOW LINE |
U+005F |
Pc, connector |
Common |
| ‿ |
UNDERTIE |
U+203F |
Pc, connector |
Common |
| ⁀ |
CHARACTER TIE |
U+2040 |
Pc, connector |
Common |
| ⁔ |
INVERTED UNDERTIE |
U+2054 |
Pc, connector |
Common |
| ︳ |
PRESENTATION FORM FOR VERTICAL LOW LINE |
U+FE33 |
Pc, connector |
Common |
| ︴ |
PRESENTATION FORM FOR VERTICAL WAVY LOW LINE |
U+FE34 |
Pc, connector |
Common |
| ﹍ |
DASHED LOW LINE |
U+FE4D |
Pc, connector |
Common |
| ﹎ |
CENTRELINE LOW LINE |
U+FE4E |
Pc, connector |
Common |
| ﹏ |
WAVY LOW LINE |
U+FE4F |
Pc, connector |
Common |
| _ |
FULLWIDTH LOW LINE |
U+FF3F |
Pc, connector |
Common |
| Po, other |
| ! |
EXCLAMATION MARK |
U+0021 |
Po, other |
Common |
| " |
QUOTATION MARK |
U+0022 |
Po, other |
Common |
| # |
NUMBER SIGN |
U+0023 |
Po, other |
Common |
| % |
PERCENT SIGN |
U+0025 |
Po, other |
Common |
| & |
AMPERSAND |
U+0026 |
Po, other |
Common |
| ' |
APOSTROPHE |
U+0027 |
Po, other |
Common |
| * |
ASTERISK |
U+002A |
Po, other |
Common |
| , |
COMMA |
U+002C |
Po, other |
Common |
| . |
FULL STOP |
U+002E |
Po, other |
Common |
| / |
SOLIDUS |
U+002F |
Po, other |
Common |
| : |
COLON |
U+003A |
Po, other |
Common |
| ; |
SEMICOLON |
U+003B |
Po, other |
Common |
| ? |
QUESTION MARK |
U+003F |
Po, other |
Common |
| @ |
COMMERCIAL AT |
U+0040 |
Po, other |
Common |
| \ |
REVERSE SOLIDUS |
U+005C |
Po, other |
Common |
| ¡ |
INVERTED EXCLAMATION MARK |
U+00A1 |
Po, other |
Common |
| § |
SECTION SIGN |
U+00A7 |
Po, other |
Common |
| ¶ |
PILCROW SIGN |
U+00B6 |
Po, other |
Common |
| · |
MIDDLE DOT |
U+00B7 |
Po, other |
Common |
| ¿ |
INVERTED QUESTION MARK |
U+00BF |
Po, other |
Common |
| ; |
GREEK QUESTION MARK |
U+037E |
Po, other |
Common |
| · |
GREEK ANO TELEIA |
U+0387 |
Po, other |
Common |
| ، |
ARABIC COMMA |
U+060C |
Po, other |
Common |
| ؛ |
ARABIC SEMICOLON |
U+061B |
Po, other |
Common |
| ؟ |
ARABIC QUESTION MARK |
U+061F |
Po, other |
Common |
| । |
DEVANAGARI DANDA |
U+0964 |
Po, other |
Common |
| ॥ |
DEVANAGARI DOUBLE DANDA |
U+0965 |
Po, other |
Common |
| ჻ |
GEORGIAN PARAGRAPH SEPARATOR |
U+10FB |
Po, other |
Common |
| ᛫ |
RUNIC SINGLE PUNCTUATION |
U+16EB |
Po, other |
Common |
| ᛬ |
RUNIC MULTIPLE PUNCTUATION |
U+16EC |
Po, other |
Common |
| ᛭ |
RUNIC CROSS PUNCTUATION |
U+16ED |
Po, other |
Common |
| ᜵ |
PHILIPPINE SINGLE PUNCTUATION |
U+1735 |
Po, other |
Common |
| ᜶ |
PHILIPPINE DOUBLE PUNCTUATION |
U+1736 |
Po, other |
Common |
| ᠂ |
MONGOLIAN COMMA |
U+1802 |
Po, other |
Common |
| ᠃ |
MONGOLIAN FULL STOP |
U+1803 |
Po, other |
Common |
| ᠅ |
MONGOLIAN FOUR DOTS |
U+1805 |
Po, other |
Common |
| ᳓ |
VEDIC SIGN NIHSHVASA |
U+1CD3 |
Po, other |
Common |
| ‖ |
DOUBLE VERTICAL LINE |
U+2016 |
Po, other |
Common |
| ‗ |
DOUBLE LOW LINE |
U+2017 |
Po, other |
Common |
| † |
DAGGER |
U+2020 |
Po, other |
Common |
| ‡ |
DOUBLE DAGGER |
U+2021 |
Po, other |
Common |
| • |
BULLET |
U+2022 |
Po, other |
Common |
| ‣ |
TRIANGULAR BULLET |
U+2023 |
Po, other |
Common |
| ․ |
ONE DOT LEADER |
U+2024 |
Po, other |
Common |
| ‥ |
TWO DOT LEADER |
U+2025 |
Po, other |
Common |
| … |
HORIZONTAL ELLIPSIS |
U+2026 |
Po, other |
Common |
| ‧ |
HYPHENATION POINT |
U+2027 |
Po, other |
Common |
| ‰ |
PER MILLE SIGN |
U+2030 |
Po, other |
Common |
| ‱ |
PER TEN THOUSAND SIGN |
U+2031 |
Po, other |
Common |
| ′ |
PRIME |
U+2032 |
Po, other |
Common |
| ″ |
DOUBLE PRIME |
U+2033 |
Po, other |
Common |
| ‴ |
TRIPLE PRIME |
U+2034 |
Po, other |
Common |
| ‵ |
REVERSED PRIME |
U+2035 |
Po, other |
Common |
| ‶ |
REVERSED DOUBLE PRIME |
U+2036 |
Po, other |
Common |
| ‷ |
REVERSED TRIPLE PRIME |
U+2037 |
Po, other |
Common |
| ‸ |
CARET |
U+2038 |
Po, other |
Common |
| ※ |
REFERENCE MARK |
U+203B |
Po, other |
Common |
| ‼ |
DOUBLE EXCLAMATION MARK |
U+203C |
Po, other |
Common |
| ‽ |
INTERROBANG |
U+203D |
Po, other |
Common |
| ‾ |
OVERLINE |
U+203E |
Po, other |
Common |
| ⁁ |
CARET INSERTION POINT |
U+2041 |
Po, other |
Common |
| ⁂ |
ASTERISM |
U+2042 |
Po, other |
Common |
| ⁃ |
HYPHEN BULLET |
U+2043 |
Po, other |
Common |
| ⁇ |
DOUBLE QUESTION MARK |
U+2047 |
Po, other |
Common |
| ⁈ |
QUESTION EXCLAMATION MARK |
U+2048 |
Po, other |
Common |
| ⁉ |
EXCLAMATION QUESTION MARK |
U+2049 |
Po, other |
Common |
| ⁊ |
TIRONIAN SIGN ET |
U+204A |
Po, other |
Common |
| ⁋ |
REVERSED PILCROW SIGN |
U+204B |
Po, other |
Common |
| ⁌ |
BLACK LEFTWARDS BULLET |
U+204C |
Po, other |
Common |
| ⁍ |
BLACK RIGHTWARDS BULLET |
U+204D |
Po, other |
Common |
| ⁎ |
LOW ASTERISK |
U+204E |
Po, other |
Common |
| ⁏ |
REVERSED SEMICOLON |
U+204F |
Po, other |
Common |
| ⁐ |
CLOSE UP |
U+2050 |
Po, other |
Common |
| ⁑ |
TWO ASTERISKS ALIGNED VERTICALLY |
U+2051 |
Po, other |
Common |
| ⁓ |
SWUNG DASH |
U+2053 |
Po, other |
Common |
| ⁕ |
FLOWER PUNCTUATION MARK |
U+2055 |
Po, other |
Common |
| ⁖ |
THREE DOT PUNCTUATION |
U+2056 |
Po, other |
Common |
| ⁗ |
QUADRUPLE PRIME |
U+2057 |
Po, other |
Common |
| ⁘ |
FOUR DOT PUNCTUATION |
U+2058 |
Po, other |
Common |
| ⁙ |
FIVE DOT PUNCTUATION |
U+2059 |
Po, other |
Common |
| ⁚ |
TWO DOT PUNCTUATION |
U+205A |
Po, other |
Common |
| ⁛ |
FOUR DOT MARK |
U+205B |
Po, other |
Common |
| ⁜ |
DOTTED CROSS |
U+205C |
Po, other |
Common |
| ⁝ |
TRICOLON |
U+205D |
Po, other |
Common |
| ⁞ |
VERTICAL FOUR DOTS |
U+205E |
Po, other |
Common |
| ⸀ |
RIGHT ANGLE SUBSTITUTION MARKER |
U+2E00 |
Po, other |
Common |
| ⸁ |
RIGHT ANGLE DOTTED SUBSTITUTION MARKER |
U+2E01 |
Po, other |
Common |
| ⸆ |
RAISED INTERPOLATION MARKER |
U+2E06 |
Po, other |
Common |
| ⸇ |
RAISED DOTTED INTERPOLATION MARKER |
U+2E07 |
Po, other |
Common |
| ⸈ |
DOTTED TRANSPOSITION MARKER |
U+2E08 |
Po, other |
Common |
| ⸋ |
RAISED SQUARE |
U+2E0B |
Po, other |
Common |
| ⸎ |
EDITORIAL CORONIS |
U+2E0E |
Po, other |
Common |
| ⸏ |
PARAGRAPHOS |
U+2E0F |
Po, other |
Common |
| ⸐ |
FORKED PARAGRAPHOS |
U+2E10 |
Po, other |
Common |
| ⸑ |
REVERSED FORKED PARAGRAPHOS |
U+2E11 |
Po, other |
Common |
| ⸒ |
HYPODIASTOLE |
U+2E12 |
Po, other |
Common |
| ⸓ |
DOTTED OBELOS |
U+2E13 |
Po, other |
Common |
| ⸔ |
DOWNWARDS ANCORA |
U+2E14 |
Po, other |
Common |
| ⸕ |
UPWARDS ANCORA |
U+2E15 |
Po, other |
Common |
| ⸖ |
DOTTED RIGHT-POINTING ANGLE |
U+2E16 |
Po, other |
Common |
| ⸘ |
INVERTED INTERROBANG |
U+2E18 |
Po, other |
Common |
| ⸙ |
PALM BRANCH |
U+2E19 |
Po, other |
Common |
| ⸛ |
TILDE WITH RING ABOVE |
U+2E1B |
Po, other |
Common |
| ⸞ |
TILDE WITH DOT ABOVE |
U+2E1E |
Po, other |
Common |
| ⸟ |
TILDE WITH DOT BELOW |
U+2E1F |
Po, other |
Common |
| ⸪ |
TWO DOTS OVER ONE DOT PUNCTUATION |
U+2E2A |
Po, other |
Common |
| ⸫ |
ONE DOT OVER TWO DOTS PUNCTUATION |
U+2E2B |
Po, other |
Common |
| ⸬ |
SQUARED FOUR DOT PUNCTUATION |
U+2E2C |
Po, other |
Common |
| ⸭ |
FIVE DOT MARK |
U+2E2D |
Po, other |
Common |
| ⸮ |
REVERSED QUESTION MARK |
U+2E2E |
Po, other |
Common |
| ⸰ |
RING POINT |
U+2E30 |
Po, other |
Common |
| ⸱ |
WORD SEPARATOR MIDDLE DOT |
U+2E31 |
Po, other |
Common |
| ⸲ |
TURNED COMMA |
U+2E32 |
Po, other |
Common |
| ⸳ |
RAISED DOT |
U+2E33 |
Po, other |
Common |
| ⸴ |
RAISED COMMA |
U+2E34 |
Po, other |
Common |
| ⸵ |
TURNED SEMICOLON |
U+2E35 |
Po, other |
Common |
| ⸶ |
DAGGER WITH LEFT GUARD |
U+2E36 |
Po, other |
Common |
| ⸷ |
DAGGER WITH RIGHT GUARD |
U+2E37 |
Po, other |
Common |
| ⸸ |
TURNED DAGGER |
U+2E38 |
Po, other |
Common |
| ⸹ |
TOP HALF SECTION SIGN |
U+2E39 |
Po, other |
Common |
| ⸼ |
STENOGRAPHIC FULL STOP |
U+2E3C |
Po, other |
Common |
| ⸽ |
VERTICAL SIX DOTS |
U+2E3D |
Po, other |
Common |
| ⸾ |
WIGGLY VERTICAL LINE |
U+2E3E |
Po, other |
Common |
| ⸿ |
CAPITULUM |
U+2E3F |
Po, other |
Common |
| ⹁ |
REVERSED COMMA |
U+2E41 |
Po, other |
Common |
| ⹃ |
DASH WITH LEFT UPTURN |
U+2E43 |
Po, other |
Common |
| ⹄ |
DOUBLE SUSPENSION MARK |
U+2E44 |
Po, other |
Common |
| ⹅ |
INVERTED LOW KAVYKA |
U+2E45 |
Po, other |
Common |
| ⹆ |
INVERTED LOW KAVYKA WITH KAVYKA ABOVE |
U+2E46 |
Po, other |
Common |
| ⹇ |
LOW KAVYKA |
U+2E47 |
Po, other |
Common |
| ⹈ |
LOW KAVYKA WITH DOT |
U+2E48 |
Po, other |
Common |
| ⹉ |
DOUBLE STACKED COMMA |
U+2E49 |
Po, other |
Common |
| ⹊ |
DOTTED SOLIDUS |
U+2E4A |
Po, other |
Common |
| ⹋ |
TRIPLE DAGGER |
U+2E4B |
Po, other |
Common |
| ⹌ |
MEDIEVAL COMMA |
U+2E4C |
Po, other |
Common |
| ⹍ |
PARAGRAPHUS MARK |
U+2E4D |
Po, other |
Common |
| ⹎ |
PUNCTUS ELEVATUS MARK |
U+2E4E |
Po, other |
Common |
| ⹏ |
CORNISH VERSE DIVIDER |
U+2E4F |
Po, other |
Common |
| ⹒ |
TIRONIAN SIGN CAPITAL ET |
U+2E52 |
Po, other |
Common |
| 、 |
IDEOGRAPHIC COMMA |
U+3001 |
Po, other |
Common |
| 。 |
IDEOGRAPHIC FULL STOP |
U+3002 |
Po, other |
Common |
| 〃 |
DITTO MARK |
U+3003 |
Po, other |
Common |
| 〽 |
PART ALTERNATION MARK |
U+303D |
Po, other |
Common |
| ・ |
KATAKANA MIDDLE DOT |
U+30FB |
Po, other |
Common |
| ꤮ |
KAYAH LI SIGN CWI |
U+A92E |
Po, other |
Common |
| ︐ |
PRESENTATION FORM FOR VERTICAL COMMA |
U+FE10 |
Po, other |
Common |
| ︑ |
PRESENTATION FORM FOR VERTICAL IDEOGRAPHIC COMMA |
U+FE11 |
Po, other |
Common |
| ︒ |
PRESENTATION FORM FOR VERTICAL IDEOGRAPHIC FULL STOP |
U+FE12 |
Po, other |
Common |
| ︓ |
PRESENTATION FORM FOR VERTICAL COLON |
U+FE13 |
Po, other |
Common |
| ︔ |
PRESENTATION FORM FOR VERTICAL SEMICOLON |
U+FE14 |
Po, other |
Common |
| ︕ |
PRESENTATION FORM FOR VERTICAL EXCLAMATION MARK |
U+FE15 |
Po, other |
Common |
| ︖ |
PRESENTATION FORM FOR VERTICAL QUESTION MARK |
U+FE16 |
Po, other |
Common |
| ︙ |
PRESENTATION FORM FOR VERTICAL HORIZONTAL ELLIPSIS |
U+FE19 |
Po, other |
Common |
| ︰ |
PRESENTATION FORM FOR VERTICAL TWO DOT LEADER |
U+FE30 |
Po, other |
Common |
| ﹅ |
SESAME DOT |
U+FE45 |
Po, other |
Common |
| ﹆ |
WHITE SESAME DOT |
U+FE46 |
Po, other |
Common |
| ﹉ |
DASHED OVERLINE |
U+FE49 |
Po, other |
Common |
| ﹊ |
CENTRELINE OVERLINE |
U+FE4A |
Po, other |
Common |
| ﹋ |
WAVY OVERLINE |
U+FE4B |
Po, other |
Common |
| ﹌ |
DOUBLE WAVY OVERLINE |
U+FE4C |
Po, other |
Common |
| ﹐ |
SMALL COMMA |
U+FE50 |
Po, other |
Common |
| ﹑ |
SMALL IDEOGRAPHIC COMMA |
U+FE51 |
Po, other |
Common |
| ﹒ |
SMALL FULL STOP |
U+FE52 |
Po, other |
Common |
| ﹔ |
SMALL SEMICOLON |
U+FE54 |
Po, other |
Common |
| ﹕ |
SMALL COLON |
U+FE55 |
Po, other |
Common |
| ﹖ |
SMALL QUESTION MARK |
U+FE56 |
Po, other |
Common |
| ﹗ |
SMALL EXCLAMATION MARK |
U+FE57 |
Po, other |
Common |
| ﹟ |
SMALL NUMBER SIGN |
U+FE5F |
Po, other |
Common |
| ﹠ |
SMALL AMPERSAND |
U+FE60 |
Po, other |
Common |
| ﹡ |
SMALL ASTERISK |
U+FE61 |
Po, other |
Common |
| ﹨ |
SMALL REVERSE SOLIDUS |
U+FE68 |
Po, other |
Common |
| ﹪ |
SMALL PERCENT SIGN |
U+FE6A |
Po, other |
Common |
| ﹫ |
SMALL COMMERCIAL AT |
U+FE6B |
Po, other |
Common |
| ! |
FULLWIDTH EXCLAMATION MARK |
U+FF01 |
Po, other |
Common |
| " |
FULLWIDTH QUOTATION MARK |
U+FF02 |
Po, other |
Common |
| # |
FULLWIDTH NUMBER SIGN |
U+FF03 |
Po, other |
Common |
| % |
FULLWIDTH PERCENT SIGN |
U+FF05 |
Po, other |
Common |
| & |
FULLWIDTH AMPERSAND |
U+FF06 |
Po, other |
Common |
| ' |
FULLWIDTH APOSTROPHE |
U+FF07 |
Po, other |
Common |
| * |
FULLWIDTH ASTERISK |
U+FF0A |
Po, other |
Common |
| , |
FULLWIDTH COMMA |
U+FF0C |
Po, other |
Common |
| . |
FULLWIDTH FULL STOP |
U+FF0E |
Po, other |
Common |
| / |
FULLWIDTH SOLIDUS |
U+FF0F |
Po, other |
Common |
| : |
FULLWIDTH COLON |
U+FF1A |
Po, other |
Common |
| ; |
FULLWIDTH SEMICOLON |
U+FF1B |
Po, other |
Common |
| ? |
FULLWIDTH QUESTION MARK |
U+FF1F |
Po, other |
Common |
| @ |
FULLWIDTH COMMERCIAL AT |
U+FF20 |
Po, other |
Common |
| \ |
FULLWIDTH REVERSE SOLIDUS |
U+FF3C |
Po, other |
Common |
| 。 |
HALFWIDTH IDEOGRAPHIC FULL STOP |
U+FF61 |
Po, other |
Common |
| 、 |
HALFWIDTH IDEOGRAPHIC COMMA |
U+FF64 |
Po, other |
Common |
| ・ |
HALFWIDTH KATAKANA MIDDLE DOT |
U+FF65 |
Po, other |
Common |
| 𐄀 |
AEGEAN WORD SEPARATOR LINE |
U+10100 |
Po, other |
Common |
| 𐄁 |
AEGEAN WORD SEPARATOR DOT |
U+10101 |
Po, other |
Common |
| 𐄂 |
AEGEAN CHECK MARK |
U+10102 |
Po, other |
Common |
| 𖿢 |
OLD CHINESE HOOK MARK |
U+16FE2 |
Po, other |
Common |
| 𞥞 |
ADLAM INITIAL EXCLAMATION MARK |
U+1E95E |
Po, other |
Adlam |
| 𞥟 |
ADLAM INITIAL QUESTION MARK |
U+1E95F |
Po, other |
Adlam |
| ՚ |
ARMENIAN APOSTROPHE |
U+055A |
Po, other |
Armenian |
| ՛ |
ARMENIAN EMPHASIS MARK |
U+055B |
Po, other |
Armenian |
| ՜ |
ARMENIAN EXCLAMATION MARK |
U+055C |
Po, other |
Armenian |
| ՝ |
ARMENIAN COMMA |
U+055D |
Po, other |
Armenian |
| ՞ |
ARMENIAN QUESTION MARK |
U+055E |
Po, other |
Armenian |
| ՟ |
ARMENIAN ABBREVIATION MARK |
U+055F |
Po, other |
Armenian |
| ։ |
ARMENIAN FULL STOP |
U+0589 |
Po, other |
Armenian |
| ؉ |
ARABIC-INDIC PER MILLE SIGN |
U+0609 |
Po, other |
Arabic |
| ؊ |
ARABIC-INDIC PER TEN THOUSAND SIGN |
U+060A |
Po, other |
Arabic |
| ؍ |
ARABIC DATE SEPARATOR |
U+060D |
Po, other |
Arabic |
| ؞ |
ARABIC TRIPLE DOT PUNCTUATION MARK |
U+061E |
Po, other |
Arabic |
| ٪ |
ARABIC PERCENT SIGN |
U+066A |
Po, other |
Arabic |
| ٫ |
ARABIC DECIMAL SEPARATOR |
U+066B |
Po, other |
Arabic |
| ٬ |
ARABIC THOUSANDS SEPARATOR |
U+066C |
Po, other |
Arabic |
| ٭ |
ARABIC FIVE POINTED STAR |
U+066D |
Po, other |
Arabic |
| ۔ |
ARABIC FULL STOP |
U+06D4 |
Po, other |
Arabic |
| 𑜼 |
AHOM SIGN SMALL SECTION |
U+1173C |
Po, other |
Ahom |
| 𑜽 |
AHOM SIGN SECTION |
U+1173D |
Po, other |
Ahom |
| 𑜾 |
AHOM SIGN RULAI |
U+1173E |
Po, other |
Ahom |
| 𐬹 |
AVESTAN ABBREVIATION MARK |
U+10B39 |
Po, other |
Avestan |
| 𐬺 |
TINY TWO DOTS OVER ONE DOT PUNCTUATION |
U+10B3A |
Po, other |
Avestan |
| 𐬻 |
SMALL TWO DOTS OVER ONE DOT PUNCTUATION |
U+10B3B |
Po, other |
Avestan |
| 𐬼 |
LARGE TWO DOTS OVER ONE DOT PUNCTUATION |
U+10B3C |
Po, other |
Avestan |
| 𐬽 |
LARGE ONE DOT OVER TWO DOTS PUNCTUATION |
U+10B3D |
Po, other |
Avestan |
| 𐬾 |
LARGE TWO RINGS OVER ONE RING PUNCTUATION |
U+10B3E |
Po, other |
Avestan |
| 𐬿 |
LARGE ONE RING OVER TWO RINGS PUNCTUATION |
U+10B3F |
Po, other |
Avestan |
| ᭚ |
BALINESE PANTI |
U+1B5A |
Po, other |
Balinese |
| ᭛ |
BALINESE PAMADA |
U+1B5B |
Po, other |
Balinese |
| ᭜ |
BALINESE WINDU |
U+1B5C |
Po, other |
Balinese |
| ᭝ |
BALINESE CARIK PAMUNGKAH |
U+1B5D |
Po, other |
Balinese |
| ᭞ |
BALINESE CARIK SIKI |
U+1B5E |
Po, other |
Balinese |
| ᭟ |
BALINESE CARIK PAREREN |
U+1B5F |
Po, other |
Balinese |
| ᭠ |
BALINESE PAMENENG |
U+1B60 |
Po, other |
Balinese |
| ꛲ |
BAMUM NJAEMLI |
U+A6F2 |
Po, other |
Bamum |
| ꛳ |
BAMUM FULL STOP |
U+A6F3 |
Po, other |
Bamum |
| ꛴ |
BAMUM COLON |
U+A6F4 |
Po, other |
Bamum |
| ꛵ |
BAMUM COMMA |
U+A6F5 |
Po, other |
Bamum |
| ꛶ |
BAMUM SEMICOLON |
U+A6F6 |
Po, other |
Bamum |
| ꛷ |
BAMUM QUESTION MARK |
U+A6F7 |
Po, other |
Bamum |
| 𖫵 |
BASSA VAH FULL STOP |
U+16AF5 |
Po, other |
Bassa Vah |
| ᯼ |
BATAK SYMBOL BINDU NA METEK |
U+1BFC |
Po, other |
Batak |
| ᯽ |
BATAK SYMBOL BINDU PINARBORAS |
U+1BFD |
Po, other |
Batak |
| ᯾ |
BATAK SYMBOL BINDU JUDUL |
U+1BFE |
Po, other |
Batak |
| ᯿ |
BATAK SYMBOL BINDU PANGOLAT |
U+1BFF |
Po, other |
Batak |
| ৽ |
BENGALI ABBREVIATION SIGN |
U+09FD |
Po, other |
Bengali |
| 𑱁 |
BHAIKSUKI DANDA |
U+11C41 |
Po, other |
Bhaiksuki |
| 𑱂 |
BHAIKSUKI DOUBLE DANDA |
U+11C42 |
Po, other |
Bhaiksuki |
| 𑱃 |
BHAIKSUKI WORD SEPARATOR |
U+11C43 |
Po, other |
Bhaiksuki |
| 𑱄 |
BHAIKSUKI GAP FILLER-1 |
U+11C44 |
Po, other |
Bhaiksuki |
| 𑱅 |
BHAIKSUKI GAP FILLER-2 |
U+11C45 |
Po, other |
Bhaiksuki |
| 𑁇 |
BRAHMI DANDA |
U+11047 |
Po, other |
Brahmi |
| 𑁈 |
BRAHMI DOUBLE DANDA |
U+11048 |
Po, other |
Brahmi |
| 𑁉 |
BRAHMI PUNCTUATION DOT |
U+11049 |
Po, other |
Brahmi |
| 𑁊 |
BRAHMI PUNCTUATION DOUBLE DOT |
U+1104A |
Po, other |
Brahmi |
| 𑁋 |
BRAHMI PUNCTUATION LINE |
U+1104B |
Po, other |
Brahmi |
| 𑁌 |
BRAHMI PUNCTUATION CRESCENT BAR |
U+1104C |
Po, other |
Brahmi |
| 𑁍 |
BRAHMI PUNCTUATION LOTUS |
U+1104D |
Po, other |
Brahmi |
| ᨞ |
BUGINESE PALLAWA |
U+1A1E |
Po, other |
Buginese |
| ᨟ |
BUGINESE END OF SECTION |
U+1A1F |
Po, other |
Buginese |
| ᙮ |
CANADIAN SYLLABICS FULL STOP |
U+166E |
Po, other |
Canadian Aboriginal |
| 𑅀 |
CHAKMA SECTION MARK |
U+11140 |
Po, other |
Chakma |
| 𑅁 |
CHAKMA DANDA |
U+11141 |
Po, other |
Chakma |
| 𑅂 |
CHAKMA DOUBLE DANDA |
U+11142 |
Po, other |
Chakma |
| 𑅃 |
CHAKMA QUESTION MARK |
U+11143 |
Po, other |
Chakma |
| ꩜ |
CHAM PUNCTUATION SPIRAL |
U+AA5C |
Po, other |
Cham |
| ꩝ |
CHAM PUNCTUATION DANDA |
U+AA5D |
Po, other |
Cham |
| ꩞ |
CHAM PUNCTUATION DOUBLE DANDA |
U+AA5E |
Po, other |
Cham |
| ꩟ |
CHAM PUNCTUATION TRIPLE DANDA |
U+AA5F |
Po, other |
Cham |
| ⳹ |
COPTIC OLD NUBIAN FULL STOP |
U+2CF9 |
Po, other |
Coptic |
| ⳺ |
COPTIC OLD NUBIAN DIRECT QUESTION MARK |
U+2CFA |
Po, other |
Coptic |
| ⳻ |
COPTIC OLD NUBIAN INDIRECT QUESTION MARK |
U+2CFB |
Po, other |
Coptic |
| ⳼ |
COPTIC OLD NUBIAN VERSE DIVIDER |
U+2CFC |
Po, other |
Coptic |
| ⳾ |
COPTIC FULL STOP |
U+2CFE |
Po, other |
Coptic |
| ⳿ |
COPTIC MORPHOLOGICAL DIVIDER |
U+2CFF |
Po, other |
Coptic |
| 𒑰 |
CUNEIFORM PUNCTUATION SIGN OLD ASSYRIAN WORD DIVIDER |
U+12470 |
Po, other |
Cuneiform |
| 𒑱 |
CUNEIFORM PUNCTUATION SIGN VERTICAL COLON |
U+12471 |
Po, other |
Cuneiform |
| 𒑲 |
CUNEIFORM PUNCTUATION SIGN DIAGONAL COLON |
U+12472 |
Po, other |
Cuneiform |
| 𒑳 |
CUNEIFORM PUNCTUATION SIGN DIAGONAL TRICOLON |
U+12473 |
Po, other |
Cuneiform |
| 𒑴 |
CUNEIFORM PUNCTUATION SIGN DIAGONAL QUADCOLON |
U+12474 |
Po, other |
Cuneiform |
| ꙳ |
SLAVONIC ASTERISK |
U+A673 |
Po, other |
Cyrillic |
| ꙾ |
CYRILLIC KAVYKA |
U+A67E |
Po, other |
Cyrillic |
| 𐕯 |
CAUCASIAN ALBANIAN CITATION MARK |
U+1056F |
Po, other |
Caucasian Albanian |
| ॰ |
DEVANAGARI ABBREVIATION SIGN |
U+0970 |
Po, other |
Devanagari |
| ꣸ |
DEVANAGARI SIGN PUSHPIKA |
U+A8F8 |
Po, other |
Devanagari |
| ꣹ |
DEVANAGARI GAP FILLER |
U+A8F9 |
Po, other |
Devanagari |
| ꣺ |
DEVANAGARI CARET |
U+A8FA |
Po, other |
Devanagari |
| ꣼ |
DEVANAGARI SIGN SIDDHAM |
U+A8FC |
Po, other |
Devanagari |
| 𑥄 |
DIVES AKURU DOUBLE DANDA |
U+11944 |
Po, other |
Dives Akuru |
| 𑥅 |
DIVES AKURU GAP FILLER |
U+11945 |
Po, other |
Dives Akuru |
| 𑥆 |
DIVES AKURU END OF TEXT MARK |
U+11946 |
Po, other |
Dives Akuru |
| 𑠻 |
DOGRA ABBREVIATION SIGN |
U+1183B |
Po, other |
Dogra |
| 𛲟 |
DUPLOYAN PUNCTUATION CHINOOK FULL STOP |
U+1BC9F |
Po, other |
Duployan |
| ፠ |
ETHIOPIC SECTION MARK |
U+1360 |
Po, other |
Ethiopic |
| ፡ |
ETHIOPIC WORDSPACE |
U+1361 |
Po, other |
Ethiopic |
| ። |
ETHIOPIC FULL STOP |
U+1362 |
Po, other |
Ethiopic |
| ፣ |
ETHIOPIC COMMA |
U+1363 |
Po, other |
Ethiopic |
| ፤ |
ETHIOPIC SEMICOLON |
U+1364 |
Po, other |
Ethiopic |
| ፥ |
ETHIOPIC COLON |
U+1365 |
Po, other |
Ethiopic |
| ፦ |
ETHIOPIC PREFACE COLON |
U+1366 |
Po, other |
Ethiopic |
| ፧ |
ETHIOPIC QUESTION MARK |
U+1367 |
Po, other |
Ethiopic |
| ፨ |
ETHIOPIC PARAGRAPH SEPARATOR |
U+1368 |
Po, other |
Ethiopic |
| ੶ |
GURMUKHI ABBREVIATION SIGN |
U+0A76 |
Po, other |
Gurmukhi |
| ૰ |
GUJARATI ABBREVIATION SIGN |
U+0AF0 |
Po, other |
Gujarati |
| ׀ |
HEBREW PUNCTUATION PASEQ |
U+05C0 |
Po, other |
Hebrew |
| ׃ |
HEBREW PUNCTUATION SOF PASUQ |
U+05C3 |
Po, other |
Hebrew |
| ׆ |
HEBREW PUNCTUATION NUN HAFUKHA |
U+05C6 |
Po, other |
Hebrew |
| ׳ |
HEBREW PUNCTUATION GERESH |
U+05F3 |
Po, other |
Hebrew |
| ״ |
HEBREW PUNCTUATION GERSHAYIM |
U+05F4 |
Po, other |
Hebrew |
| 𐡗 |
IMPERIAL ARAMAIC SECTION SIGN |
U+10857 |
Po, other |
Imperial Aramaic |
| ꧁ |
JAVANESE LEFT RERENGGAN |
U+A9C1 |
Po, other |
Javanese |
| ꧂ |
JAVANESE RIGHT RERENGGAN |
U+A9C2 |
Po, other |
Javanese |
| ꧃ |
JAVANESE PADA ANDAP |
U+A9C3 |
Po, other |
Javanese |
| ꧄ |
JAVANESE PADA MADYA |
U+A9C4 |
Po, other |
Javanese |
| ꧅ |
JAVANESE PADA LUHUR |
U+A9C5 |
Po, other |
Javanese |
| ꧆ |
JAVANESE PADA WINDU |
U+A9C6 |
Po, other |
Javanese |
| ꧇ |
JAVANESE PADA PANGKAT |
U+A9C7 |
Po, other |
Javanese |
| ꧈ |
JAVANESE PADA LINGSA |
U+A9C8 |
Po, other |
Javanese |
| ꧉ |
JAVANESE PADA LUNGSI |
U+A9C9 |
Po, other |
Javanese |
| ꧊ |
JAVANESE PADA ADEG |
U+A9CA |
Po, other |
Javanese |
| ꧋ |
JAVANESE PADA ADEG ADEG |
U+A9CB |
Po, other |
Javanese |
| ꧌ |
JAVANESE PADA PISELEH |
U+A9CC |
Po, other |
Javanese |
| ꧍ |
JAVANESE TURNED PADA PISELEH |
U+A9CD |
Po, other |
Javanese |
| ꧞ |
JAVANESE PADA TIRTA TUMETES |
U+A9DE |
Po, other |
Javanese |
| ꧟ |
JAVANESE PADA ISEN-ISEN |
U+A9DF |
Po, other |
Javanese |
| 𑂻 |
KAITHI ABBREVIATION SIGN |
U+110BB |
Po, other |
Kaithi |
| 𑂼 |
KAITHI ENUMERATION SIGN |
U+110BC |
Po, other |
Kaithi |
| 𑂾 |
KAITHI SECTION MARK |
U+110BE |
Po, other |
Kaithi |
| 𑂿 |
KAITHI DOUBLE SECTION MARK |
U+110BF |
Po, other |
Kaithi |
| 𑃀 |
KAITHI DANDA |
U+110C0 |
Po, other |
Kaithi |
| 𑃁 |
KAITHI DOUBLE DANDA |
U+110C1 |
Po, other |
Kaithi |
| ಄ |
KANNADA SIGN SIDDHAM |
U+0C84 |
Po, other |
Kannada |
| ꤯ |
KAYAH LI SIGN SHYA |
U+A92F |
Po, other |
Kayah Li |
| 𐩐 |
KHAROSHTHI PUNCTUATION DOT |
U+10A50 |
Po, other |
Kharoshthi |
| 𐩑 |
KHAROSHTHI PUNCTUATION SMALL CIRCLE |
U+10A51 |
Po, other |
Kharoshthi |
| 𐩒 |
KHAROSHTHI PUNCTUATION CIRCLE |
U+10A52 |
Po, other |
Kharoshthi |
| 𐩓 |
KHAROSHTHI PUNCTUATION CRESCENT BAR |
U+10A53 |
Po, other |
Kharoshthi |
| 𐩔 |
KHAROSHTHI PUNCTUATION MANGALAM |
U+10A54 |
Po, other |
Kharoshthi |
| 𐩕 |
KHAROSHTHI PUNCTUATION LOTUS |
U+10A55 |
Po, other |
Kharoshthi |
| 𐩖 |
KHAROSHTHI PUNCTUATION DANDA |
U+10A56 |
Po, other |
Kharoshthi |
| 𐩗 |
KHAROSHTHI PUNCTUATION DOUBLE DANDA |
U+10A57 |
Po, other |
Kharoshthi |
| 𐩘 |
KHAROSHTHI PUNCTUATION LINES |
U+10A58 |
Po, other |
Kharoshthi |
| ។ |
KHMER SIGN KHAN |
U+17D4 |
Po, other |
Khmer |
| ៕ |
KHMER SIGN BARIYOOSAN |
U+17D5 |
Po, other |
Khmer |
| ៖ |
KHMER SIGN CAMNUC PII KUUH |
U+17D6 |
Po, other |
Khmer |
| ៘ |
KHMER SIGN BEYYAL |
U+17D8 |
Po, other |
Khmer |
| ៙ |
KHMER SIGN PHNAEK MUAN |
U+17D9 |
Po, other |
Khmer |
| ៚ |
KHMER SIGN KOOMUUT |
U+17DA |
Po, other |
Khmer |
| 𑈸 |
KHOJKI DANDA |
U+11238 |
Po, other |
Khojki |
| 𑈹 |
KHOJKI DOUBLE DANDA |
U+11239 |
Po, other |
Khojki |
| 𑈺 |
KHOJKI WORD SEPARATOR |
U+1123A |
Po, other |
Khojki |
| 𑈻 |
KHOJKI SECTION MARK |
U+1123B |
Po, other |
Khojki |
| 𑈼 |
KHOJKI DOUBLE SECTION MARK |
U+1123C |
Po, other |
Khojki |
| 𑈽 |
KHOJKI ABBREVIATION SIGN |
U+1123D |
Po, other |
Khojki |
| ᰻ |
LEPCHA PUNCTUATION TA-ROL |
U+1C3B |
Po, other |
Lepcha |
| ᰼ |
LEPCHA PUNCTUATION NYET THYOOM TA-ROL |
U+1C3C |
Po, other |
Lepcha |
| ᰽ |
LEPCHA PUNCTUATION CER-WA |
U+1C3D |
Po, other |
Lepcha |
| ᰾ |
LEPCHA PUNCTUATION TSHOOK CER-WA |
U+1C3E |
Po, other |
Lepcha |
| ᰿ |
LEPCHA PUNCTUATION TSHOOK |
U+1C3F |
Po, other |
Lepcha |
| ᥄ |
LIMBU EXCLAMATION MARK |
U+1944 |
Po, other |
Limbu |
| ᥅ |
LIMBU QUESTION MARK |
U+1945 |
Po, other |
Limbu |
| ꓾ |
LISU PUNCTUATION COMMA |
U+A4FE |
Po, other |
Lisu |
| ꓿ |
LISU PUNCTUATION FULL STOP |
U+A4FF |
Po, other |
Lisu |
| 𐤿 |
LYDIAN TRIANGULAR MARK |
U+1093F |
Po, other |
Lydian |
| 𑅴 |
MAHAJANI ABBREVIATION SIGN |
U+11174 |
Po, other |
Mahajani |
| 𑅵 |
MAHAJANI SECTION MARK |
U+11175 |
Po, other |
Mahajani |
| 𑻷 |
MAKASAR PASSIMBANG |
U+11EF7 |
Po, other |
Makasar |
| 𑻸 |
MAKASAR END OF SECTION |
U+11EF8 |
Po, other |
Makasar |
| 𐫰 |
MANICHAEAN PUNCTUATION STAR |
U+10AF0 |
Po, other |
Manichaean |
| 𐫱 |
MANICHAEAN PUNCTUATION FLEURON |
U+10AF1 |
Po, other |
Manichaean |
| 𐫲 |
MANICHAEAN PUNCTUATION DOUBLE DOT WITHIN DOT |
U+10AF2 |
Po, other |
Manichaean |
| 𐫳 |
MANICHAEAN PUNCTUATION DOT WITHIN DOT |
U+10AF3 |
Po, other |
Manichaean |
| 𐫴 |
MANICHAEAN PUNCTUATION DOT |
U+10AF4 |
Po, other |
Manichaean |
| 𐫵 |
MANICHAEAN PUNCTUATION TWO DOTS |
U+10AF5 |
Po, other |
Manichaean |
| 𐫶 |
MANICHAEAN PUNCTUATION LINE FILLER |
U+10AF6 |
Po, other |
Manichaean |
| 𑱰 |
MARCHEN HEAD MARK |
U+11C70 |
Po, other |
Marchen |
| 𑱱 |
MARCHEN MARK SHAD |
U+11C71 |
Po, other |
Marchen |
| 𖺗 |
MEDEFAIDRIN COMMA |
U+16E97 |
Po, other |
Medefaidrin |
| 𖺘 |
MEDEFAIDRIN FULL STOP |
U+16E98 |
Po, other |
Medefaidrin |
| 𖺙 |
MEDEFAIDRIN SYMBOL AIVA |
U+16E99 |
Po, other |
Medefaidrin |
| 𖺚 |
MEDEFAIDRIN EXCLAMATION OH |
U+16E9A |
Po, other |
Medefaidrin |
| ꫰ |
MEETEI MAYEK CHEIKHAN |
U+AAF0 |
Po, other |
Meetei Mayek |
| ꫱ |
MEETEI MAYEK AHANG KHUDAM |
U+AAF1 |
Po, other |
Meetei Mayek |
| ꯫ |
MEETEI MAYEK CHEIKHEI |
U+ABEB |
Po, other |
Meetei Mayek |
| 𑙁 |
MODI DANDA |
U+11641 |
Po, other |
Modi |
| 𑙂 |
MODI DOUBLE DANDA |
U+11642 |
Po, other |
Modi |
| 𑙃 |
MODI ABBREVIATION SIGN |
U+11643 |
Po, other |
Modi |
| ᠀ |
MONGOLIAN BIRGA |
U+1800 |
Po, other |
Mongolian |
| ᠁ |
MONGOLIAN ELLIPSIS |
U+1801 |
Po, other |
Mongolian |
| ᠄ |
MONGOLIAN COLON |
U+1804 |
Po, other |
Mongolian |
| ᠇ |
MONGOLIAN SIBE SYLLABLE BOUNDARY MARKER |
U+1807 |
Po, other |
Mongolian |
| ᠈ |
MONGOLIAN MANCHU COMMA |
U+1808 |
Po, other |
Mongolian |
| ᠉ |
MONGOLIAN MANCHU FULL STOP |
U+1809 |
Po, other |
Mongolian |
| ᠊ |
MONGOLIAN NIRUGU |
U+180A |
Po, other |
Mongolian |
| 𑙠 |
MONGOLIAN BIRGA WITH ORNAMENT |
U+11660 |
Po, other |
Mongolian |
| 𑙡 |
MONGOLIAN ROTATED BIRGA |
U+11661 |
Po, other |
Mongolian |
| 𑙢 |
MONGOLIAN DOUBLE BIRGA WITH ORNAMENT |
U+11662 |
Po, other |
Mongolian |
| 𑙣 |
MONGOLIAN TRIPLE BIRGA WITH ORNAMENT |
U+11663 |
Po, other |
Mongolian |
| 𑙤 |
MONGOLIAN BIRGA WITH DOUBLE ORNAMENT |
U+11664 |
Po, other |
Mongolian |
| 𑙥 |
MONGOLIAN ROTATED BIRGA WITH ORNAMENT |
U+11665 |
Po, other |
Mongolian |
| 𑙦 |
MONGOLIAN ROTATED BIRGA WITH DOUBLE ORNAMENT |
U+11666 |
Po, other |
Mongolian |
| 𑙧 |
MONGOLIAN INVERTED BIRGA |
U+11667 |
Po, other |
Mongolian |
| 𑙨 |
MONGOLIAN INVERTED BIRGA WITH DOUBLE ORNAMENT |
U+11668 |
Po, other |
Mongolian |
| 𑙩 |
MONGOLIAN SWIRL BIRGA |
U+11669 |
Po, other |
Mongolian |
| 𑙪 |
MONGOLIAN SWIRL BIRGA WITH ORNAMENT |
U+1166A |
Po, other |
Mongolian |
| 𑙫 |
MONGOLIAN SWIRL BIRGA WITH DOUBLE ORNAMENT |
U+1166B |
Po, other |
Mongolian |
| 𑙬 |
MONGOLIAN TURNED SWIRL BIRGA WITH DOUBLE ORNAMENT |
U+1166C |
Po, other |
Mongolian |
| 𖩮 |
MRO DANDA |
U+16A6E |
Po, other |
Mro |
| 𖩯 |
MRO DOUBLE DANDA |
U+16A6F |
Po, other |
Mro |
| 𑊩 |
MULTANI SECTION MARK |
U+112A9 |
Po, other |
Multani |
| ၊ |
MYANMAR SIGN LITTLE SECTION |
U+104A |
Po, other |
Myanmar |
| ။ |
MYANMAR SIGN SECTION |
U+104B |
Po, other |
Myanmar |
| ၌ |
MYANMAR SYMBOL LOCATIVE |
U+104C |
Po, other |
Myanmar |
| ၍ |
MYANMAR SYMBOL COMPLETED |
U+104D |
Po, other |
Myanmar |
| ၎ |
MYANMAR SYMBOL AFOREMENTIONED |
U+104E |
Po, other |
Myanmar |
| ၏ |
MYANMAR SYMBOL GENITIVE |
U+104F |
Po, other |
Myanmar |
| ߷ |
NKO SYMBOL GBAKURUNEN |
U+07F7 |
Po, other |
N'Ko |
| ߸ |
NKO COMMA |
U+07F8 |
Po, other |
N'Ko |
| ߹ |
NKO EXCLAMATION MARK |
U+07F9 |
Po, other |
N'Ko |
| 𑧢 |
NANDINAGARI SIGN SIDDHAM |
U+119E2 |
Po, other |
Nandinagari |
| 𑑋 |
NEWA DANDA |
U+1144B |
Po, other |
Newa |
| 𑑌 |
NEWA DOUBLE DANDA |
U+1144C |
Po, other |
Newa |
| 𑑍 |
NEWA COMMA |
U+1144D |
Po, other |
Newa |
| 𑑎 |
NEWA GAP FILLER |
U+1144E |
Po, other |
Newa |
| 𑑏 |
NEWA ABBREVIATION SIGN |
U+1144F |
Po, other |
Newa |
| 𑑚 |
NEWA DOUBLE COMMA |
U+1145A |
Po, other |
Newa |
| 𑑛 |
NEWA PLACEHOLDER MARK |
U+1145B |
Po, other |
Newa |
| 𑑝 |
NEWA INSERTION SIGN |
U+1145D |
Po, other |
Newa |
| ᱾ |
OL CHIKI PUNCTUATION MUCAAD |
U+1C7E |
Po, other |
Ol Chiki |
| ᱿ |
OL CHIKI PUNCTUATION DOUBLE MUCAAD |
U+1C7F |
Po, other |
Ol Chiki |
| 𐏐 |
OLD PERSIAN WORD DIVIDER |
U+103D0 |
Po, other |
Old Persian |
| 𐩿 |
OLD SOUTH ARABIAN NUMERIC INDICATOR |
U+10A7F |
Po, other |
Old South Arabian |
| 𖬷 |
PAHAWH HMONG SIGN VOS THOM |
U+16B37 |
Po, other |
Pahawh Hmong |
| 𖬸 |
PAHAWH HMONG SIGN VOS TSHAB CEEB |
U+16B38 |
Po, other |
Pahawh Hmong |
| 𖬹 |
PAHAWH HMONG SIGN CIM CHEEM |
U+16B39 |
Po, other |
Pahawh Hmong |
| 𖬺 |
PAHAWH HMONG SIGN VOS THIAB |
U+16B3A |
Po, other |
Pahawh Hmong |
| 𖬻 |
PAHAWH HMONG SIGN VOS FEEM |
U+16B3B |
Po, other |
Pahawh Hmong |
| 𖭄 |
PAHAWH HMONG SIGN XAUS |
U+16B44 |
Po, other |
Pahawh Hmong |
| ꡴ |
PHAGS-PA SINGLE HEAD MARK |
U+A874 |
Po, other |
Phags-pa |
| ꡵ |
PHAGS-PA DOUBLE HEAD MARK |
U+A875 |
Po, other |
Phags-pa |
| ꡶ |
PHAGS-PA MARK SHAD |
U+A876 |
Po, other |
Phags-pa |
| ꡷ |
PHAGS-PA MARK DOUBLE SHAD |
U+A877 |
Po, other |
Phags-pa |
| 𐤟 |
PHOENICIAN WORD SEPARATOR |
U+1091F |
Po, other |
Phoenician |
| 𐮙 |
PSALTER PAHLAVI SECTION MARK |
U+10B99 |
Po, other |
Psalter Pahlavi |
| 𐮚 |
PSALTER PAHLAVI TURNED SECTION MARK |
U+10B9A |
Po, other |
Psalter Pahlavi |
| 𐮛 |
PSALTER PAHLAVI FOUR DOTS WITH CROSS |
U+10B9B |
Po, other |
Psalter Pahlavi |
| 𐮜 |
PSALTER PAHLAVI FOUR DOTS WITH DOT |
U+10B9C |
Po, other |
Psalter Pahlavi |
| ꥟ |
REJANG SECTION MARK |
U+A95F |
Po, other |
Rejang |
| ࠰ |
SAMARITAN PUNCTUATION NEQUDAA |
U+0830 |
Po, other |
Samaritan |
| ࠱ |
SAMARITAN PUNCTUATION AFSAAQ |
U+0831 |
Po, other |
Samaritan |
| ࠲ |
SAMARITAN PUNCTUATION ANGED |
U+0832 |
Po, other |
Samaritan |
| ࠳ |
SAMARITAN PUNCTUATION BAU |
U+0833 |
Po, other |
Samaritan |
| ࠴ |
SAMARITAN PUNCTUATION ATMAAU |
U+0834 |
Po, other |
Samaritan |
| ࠵ |
SAMARITAN PUNCTUATION SHIYYAALAA |
U+0835 |
Po, other |
Samaritan |
| ࠶ |
SAMARITAN ABBREVIATION MARK |
U+0836 |
Po, other |
Samaritan |
| ࠷ |
SAMARITAN PUNCTUATION MELODIC QITSA |
U+0837 |
Po, other |
Samaritan |
| ࠸ |
SAMARITAN PUNCTUATION ZIQAA |
U+0838 |
Po, other |
Samaritan |
| ࠹ |
SAMARITAN PUNCTUATION QITSA |
U+0839 |
Po, other |
Samaritan |
| ࠺ |
SAMARITAN PUNCTUATION ZAEF |
U+083A |
Po, other |
Samaritan |
| ࠻ |
SAMARITAN PUNCTUATION TURU |
U+083B |
Po, other |
Samaritan |
| ࠼ |
SAMARITAN PUNCTUATION ARKAANU |
U+083C |
Po, other |
Samaritan |
| ࠽ |
SAMARITAN PUNCTUATION SOF MASHFAAT |
U+083D |
Po, other |
Samaritan |
| ࠾ |
SAMARITAN PUNCTUATION ANNAAU |
U+083E |
Po, other |
Samaritan |
| ꣎ |
SAURASHTRA DANDA |
U+A8CE |
Po, other |
Saurashtra |
| ꣏ |
SAURASHTRA DOUBLE DANDA |
U+A8CF |
Po, other |
Saurashtra |
| 𑇅 |
SHARADA DANDA |
U+111C5 |
Po, other |
Sharada |
| 𑇆 |
SHARADA DOUBLE DANDA |
U+111C6 |
Po, other |
Sharada |
| 𑇇 |
SHARADA ABBREVIATION SIGN |
U+111C7 |
Po, other |
Sharada |
| 𑇈 |
SHARADA SEPARATOR |
U+111C8 |
Po, other |
Sharada |
| 𑇍 |
SHARADA SUTRA MARK |
U+111CD |
Po, other |
Sharada |
| 𑇛 |
SHARADA SIGN SIDDHAM |
U+111DB |
Po, other |
Sharada |
| 𑇝 |
SHARADA CONTINUATION SIGN |
U+111DD |
Po, other |
Sharada |
| 𑇞 |
SHARADA SECTION MARK-1 |
U+111DE |
Po, other |
Sharada |
| 𑇟 |
SHARADA SECTION MARK-2 |
U+111DF |
Po, other |
Sharada |
| 𑗁 |
SIDDHAM SIGN SIDDHAM |
U+115C1 |
Po, other |
Siddham |
| 𑗂 |
SIDDHAM DANDA |
U+115C2 |
Po, other |
Siddham |
| 𑗃 |
SIDDHAM DOUBLE DANDA |
U+115C3 |
Po, other |
Siddham |
| 𑗄 |
SIDDHAM SEPARATOR DOT |
U+115C4 |
Po, other |
Siddham |
| 𑗅 |
SIDDHAM SEPARATOR BAR |
U+115C5 |
Po, other |
Siddham |
| 𑗆 |
SIDDHAM REPETITION MARK-1 |
U+115C6 |
Po, other |
Siddham |
| 𑗇 |
SIDDHAM REPETITION MARK-2 |
U+115C7 |
Po, other |
Siddham |
| 𑗈 |
SIDDHAM REPETITION MARK-3 |
U+115C8 |
Po, other |
Siddham |
| 𑗉 |
SIDDHAM END OF TEXT MARK |
U+115C9 |
Po, other |
Siddham |
| 𑗊 |
SIDDHAM SECTION MARK WITH TRIDENT AND U-SHAPED ORNAMENTS |
U+115CA |
Po, other |
Siddham |
| 𑗋 |
SIDDHAM SECTION MARK WITH TRIDENT AND DOTTED CRESCENTS |
U+115CB |
Po, other |
Siddham |
| 𑗌 |
SIDDHAM SECTION MARK WITH RAYS AND DOTTED CRESCENTS |
U+115CC |
Po, other |
Siddham |
| 𑗍 |
SIDDHAM SECTION MARK WITH RAYS AND DOTTED DOUBLE CRESCENTS |
U+115CD |
Po, other |
Siddham |
| 𑗎 |
SIDDHAM SECTION MARK WITH RAYS AND DOTTED TRIPLE CRESCENTS |
U+115CE |
Po, other |
Siddham |
| 𑗏 |
SIDDHAM SECTION MARK DOUBLE RING |
U+115CF |
Po, other |
Siddham |
| 𑗐 |
SIDDHAM SECTION MARK DOUBLE RING WITH RAYS |
U+115D0 |
Po, other |
Siddham |
| 𑗑 |
SIDDHAM SECTION MARK WITH DOUBLE CRESCENTS |
U+115D1 |
Po, other |
Siddham |
| 𑗒 |
SIDDHAM SECTION MARK WITH TRIPLE CRESCENTS |
U+115D2 |
Po, other |
Siddham |
| 𑗓 |
SIDDHAM SECTION MARK WITH QUADRUPLE CRESCENTS |
U+115D3 |
Po, other |
Siddham |
| 𑗔 |
SIDDHAM SECTION MARK WITH SEPTUPLE CRESCENTS |
U+115D4 |
Po, other |
Siddham |
| 𑗕 |
SIDDHAM SECTION MARK WITH CIRCLES AND RAYS |
U+115D5 |
Po, other |
Siddham |
| 𑗖 |
SIDDHAM SECTION MARK WITH CIRCLES AND TWO ENCLOSURES |
U+115D6 |
Po, other |
Siddham |
| 𑗗 |
SIDDHAM SECTION MARK WITH CIRCLES AND FOUR ENCLOSURES |
U+115D7 |
Po, other |
Siddham |
| 𝪇 |
SIGNWRITING COMMA |
U+1DA87 |
Po, other |
SignWriting |
| 𝪈 |
SIGNWRITING FULL STOP |
U+1DA88 |
Po, other |
SignWriting |
| 𝪉 |
SIGNWRITING SEMICOLON |
U+1DA89 |
Po, other |
SignWriting |
| 𝪊 |
SIGNWRITING COLON |
U+1DA8A |
Po, other |
SignWriting |
| 𝪋 |
SIGNWRITING PARENTHESIS |
U+1DA8B |
Po, other |
SignWriting |
| ෴ |
SINHALA PUNCTUATION KUNDDALIYA |
U+0DF4 |
Po, other |
Sinhala |
| 𐽕 |
SOGDIAN PUNCTUATION TWO VERTICAL BARS |
U+10F55 |
Po, other |
Sogdian |
| 𐽖 |
SOGDIAN PUNCTUATION TWO VERTICAL BARS WITH DOTS |
U+10F56 |
Po, other |
Sogdian |
| 𐽗 |
SOGDIAN PUNCTUATION CIRCLE WITH DOT |
U+10F57 |
Po, other |
Sogdian |
| 𐽘 |
SOGDIAN PUNCTUATION TWO CIRCLES WITH DOTS |
U+10F58 |
Po, other |
Sogdian |
| 𐽙 |
SOGDIAN PUNCTUATION HALF CIRCLE WITH DOT |
U+10F59 |
Po, other |
Sogdian |
| 𑪚 |
SOYOMBO MARK TSHEG |
U+11A9A |
Po, other |
Soyombo |
| 𑪛 |
SOYOMBO MARK SHAD |
U+11A9B |
Po, other |
Soyombo |
| 𑪜 |
SOYOMBO MARK DOUBLE SHAD |
U+11A9C |
Po, other |
Soyombo |
| 𑪞 |
SOYOMBO HEAD MARK WITH MOON AND SUN AND TRIPLE FLAME |
U+11A9E |
Po, other |
Soyombo |
| 𑪟 |
SOYOMBO HEAD MARK WITH MOON AND SUN AND FLAME |
U+11A9F |
Po, other |
Soyombo |
| 𑪠 |
SOYOMBO HEAD MARK WITH MOON AND SUN |
U+11AA0 |
Po, other |
Soyombo |
| 𑪡 |
SOYOMBO TERMINAL MARK-1 |
U+11AA1 |
Po, other |
Soyombo |
| 𑪢 |
SOYOMBO TERMINAL MARK-2 |
U+11AA2 |
Po, other |
Soyombo |
| ᳀ |
SUNDANESE PUNCTUATION BINDU SURYA |
U+1CC0 |
Po, other |
Sundanese |
| ᳁ |
SUNDANESE PUNCTUATION BINDU PANGLONG |
U+1CC1 |
Po, other |
Sundanese |
| ᳂ |
SUNDANESE PUNCTUATION BINDU PURNAMA |
U+1CC2 |
Po, other |
Sundanese |
| ᳃ |
SUNDANESE PUNCTUATION BINDU CAKRA |
U+1CC3 |
Po, other |
Sundanese |
| ᳄ |
SUNDANESE PUNCTUATION BINDU LEU SATANGA |
U+1CC4 |
Po, other |
Sundanese |
| ᳅ |
SUNDANESE PUNCTUATION BINDU KA SATANGA |
U+1CC5 |
Po, other |
Sundanese |
| ᳆ |
SUNDANESE PUNCTUATION BINDU DA SATANGA |
U+1CC6 |
Po, other |
Sundanese |
| ᳇ |
SUNDANESE PUNCTUATION BINDU BA SATANGA |
U+1CC7 |
Po, other |
Sundanese |
| ܀ |
SYRIAC END OF PARAGRAPH |
U+0700 |
Po, other |
Syriac |
| ܁ |
SYRIAC SUPRALINEAR FULL STOP |
U+0701 |
Po, other |
Syriac |
| ܂ |
SYRIAC SUBLINEAR FULL STOP |
U+0702 |
Po, other |
Syriac |
| ܃ |
SYRIAC SUPRALINEAR COLON |
U+0703 |
Po, other |
Syriac |
| ܄ |
SYRIAC SUBLINEAR COLON |
U+0704 |
Po, other |
Syriac |
| ܅ |
SYRIAC HORIZONTAL COLON |
U+0705 |
Po, other |
Syriac |
| ܆ |
SYRIAC COLON SKEWED LEFT |
U+0706 |
Po, other |
Syriac |
| ܇ |
SYRIAC COLON SKEWED RIGHT |
U+0707 |
Po, other |
Syriac |
| ܈ |
SYRIAC SUPRALINEAR COLON SKEWED LEFT |
U+0708 |
Po, other |
Syriac |
| ܉ |
SYRIAC SUBLINEAR COLON SKEWED RIGHT |
U+0709 |
Po, other |
Syriac |
| ܊ |
SYRIAC CONTRACTION |
U+070A |
Po, other |
Syriac |
| ܋ |
SYRIAC HARKLEAN OBELUS |
U+070B |
Po, other |
Syriac |
| ܌ |
SYRIAC HARKLEAN METOBELUS |
U+070C |
Po, other |
Syriac |
| ܍ |
SYRIAC HARKLEAN ASTERISCUS |
U+070D |
Po, other |
Syriac |
| ᪠ |
TAI THAM SIGN WIANG |
U+1AA0 |
Po, other |
Tai Tham |
| ᪡ |
TAI THAM SIGN WIANGWAAK |
U+1AA1 |
Po, other |
Tai Tham |
| ᪢ |
TAI THAM SIGN SAWAN |
U+1AA2 |
Po, other |
Tai Tham |
| ᪣ |
TAI THAM SIGN KEOW |
U+1AA3 |
Po, other |
Tai Tham |
| ᪤ |
TAI THAM SIGN HOY |
U+1AA4 |
Po, other |
Tai Tham |
| ᪥ |
TAI THAM SIGN DOKMAI |
U+1AA5 |
Po, other |
Tai Tham |
| ᪦ |
TAI THAM SIGN REVERSED ROTATED RANA |
U+1AA6 |
Po, other |
Tai Tham |
| ᪨ |
TAI THAM SIGN KAAN |
U+1AA8 |
Po, other |
Tai Tham |
| ᪩ |
TAI THAM SIGN KAANKUU |
U+1AA9 |
Po, other |
Tai Tham |
| ᪪ |
TAI THAM SIGN SATKAAN |
U+1AAA |
Po, other |
Tai Tham |
| ᪫ |
TAI THAM SIGN SATKAANKUU |
U+1AAB |
Po, other |
Tai Tham |
| ᪬ |
TAI THAM SIGN HANG |
U+1AAC |
Po, other |
Tai Tham |
| ᪭ |
TAI THAM SIGN CAANG |
U+1AAD |
Po, other |
Tai Tham |
| ꫞ |
TAI VIET SYMBOL HO HOI |
U+AADE |
Po, other |
Tai Viet |
| ꫟ |
TAI VIET SYMBOL KOI KOI |
U+AADF |
Po, other |
Tai Viet |
| 𑿿 |
TAMIL PUNCTUATION END OF TEXT |
U+11FFF |
Po, other |
Tamil |
| ౷ |
TELUGU SIGN SIDDHAM |
U+0C77 |
Po, other |
Telugu |
| ๏ |
THAI CHARACTER FONGMAN |
U+0E4F |
Po, other |
Thai |
| ๚ |
THAI CHARACTER ANGKHANKHU |
U+0E5A |
Po, other |
Thai |
| ๛ |
THAI CHARACTER KHOMUT |
U+0E5B |
Po, other |
Thai |
| ༄ |
TIBETAN MARK INITIAL YIG MGO MDUN MA |
U+0F04 |
Po, other |
Tibetan |
| ༅ |
TIBETAN MARK CLOSING YIG MGO SGAB MA |
U+0F05 |
Po, other |
Tibetan |
| ༆ |
TIBETAN MARK CARET YIG MGO PHUR SHAD MA |
U+0F06 |
Po, other |
Tibetan |
| ༇ |
TIBETAN MARK YIG MGO TSHEG SHAD MA |
U+0F07 |
Po, other |
Tibetan |
| ༈ |
TIBETAN MARK SBRUL SHAD |
U+0F08 |
Po, other |
Tibetan |
| ༉ |
TIBETAN MARK BSKUR YIG MGO |
U+0F09 |
Po, other |
Tibetan |
| ༊ |
TIBETAN MARK BKA- SHOG YIG MGO |
U+0F0A |
Po, other |
Tibetan |
| ་ |
TIBETAN MARK INTERSYLLABIC TSHEG |
U+0F0B |
Po, other |
Tibetan |
| ༌ |
TIBETAN MARK DELIMITER TSHEG BSTAR |
U+0F0C |
Po, other |
Tibetan |
| ། |
TIBETAN MARK SHAD |
U+0F0D |
Po, other |
Tibetan |
| ༎ |
TIBETAN MARK NYIS SHAD |
U+0F0E |
Po, other |
Tibetan |
| ༏ |
TIBETAN MARK TSHEG SHAD |
U+0F0F |
Po, other |
Tibetan |
| ༐ |
TIBETAN MARK NYIS TSHEG SHAD |
U+0F10 |
Po, other |
Tibetan |
| ༑ |
TIBETAN MARK RIN CHEN SPUNGS SHAD |
U+0F11 |
Po, other |
Tibetan |
| ༒ |
TIBETAN MARK RGYA GRAM SHAD |
U+0F12 |
Po, other |
Tibetan |
| ༔ |
TIBETAN MARK GTER TSHEG |
U+0F14 |
Po, other |
Tibetan |
| ྅ |
TIBETAN MARK PALUTA |
U+0F85 |
Po, other |
Tibetan |
| ࿐ |
TIBETAN MARK BSKA- SHOG GI MGO RGYAN |
U+0FD0 |
Po, other |
Tibetan |
| ࿑ |
TIBETAN MARK MNYAM YIG GI MGO RGYAN |
U+0FD1 |
Po, other |
Tibetan |
| ࿒ |
TIBETAN MARK NYIS TSHEG |
U+0FD2 |
Po, other |
Tibetan |
| ࿓ |
TIBETAN MARK INITIAL BRDA RNYING YIG MGO MDUN MA |
U+0FD3 |
Po, other |
Tibetan |
| ࿔ |
TIBETAN MARK CLOSING BRDA RNYING YIG MGO SGAB MA |
U+0FD4 |
Po, other |
Tibetan |
| ࿙ |
TIBETAN MARK LEADING MCHAN RTAGS |
U+0FD9 |
Po, other |
Tibetan |
| ࿚ |
TIBETAN MARK TRAILING MCHAN RTAGS |
U+0FDA |
Po, other |
Tibetan |
| ⵰ |
TIFINAGH SEPARATOR MARK |
U+2D70 |
Po, other |
Tifinagh |
| 𑓆 |
TIRHUTA ABBREVIATION SIGN |
U+114C6 |
Po, other |
Tirhuta |
| 𐎟 |
UGARITIC WORD DIVIDER |
U+1039F |
Po, other |
Ugaritic |
| ꘍ |
VAI COMMA |
U+A60D |
Po, other |
Vai |
| ꘎ |
VAI FULL STOP |
U+A60E |
Po, other |
Vai |
| ꘏ |
VAI QUESTION MARK |
U+A60F |
Po, other |
Vai |
| 𑨿 |
ZANABAZAR SQUARE INITIAL HEAD MARK |
U+11A3F |
Po, other |
Zanabazar Square |
| 𑩀 |
ZANABAZAR SQUARE CLOSING HEAD MARK |
U+11A40 |
Po, other |
Zanabazar Square |
| 𑩁 |
ZANABAZAR SQUARE MARK TSHEG |
U+11A41 |
Po, other |
Zanabazar Square |
| 𑩂 |
ZANABAZAR SQUARE MARK SHAD |
U+11A42 |
Po, other |
Zanabazar Square |
| 𑩃 |
ZANABAZAR SQUARE MARK DOUBLE SHAD |
U+11A43 |
Po, other |
Zanabazar Square |
| 𑩄 |
ZANABAZAR SQUARE MARK LONG TSHEG |
U+11A44 |
Po, other |
Zanabazar Square |
| 𑩅 |
ZANABAZAR SQUARE INITIAL DOUBLE-LINED HEAD MARK |
U+11A45 |
Po, other |
Zanabazar Square |
| 𑩆 |
ZANABAZAR SQUARE CLOSING DOUBLE-LINED HEAD MARK |
U+11A46 |
Po, other |
Zanabazar Square |
| ࡞ |
MANDAIC PUNCTUATION |
U+085E |
Po, other |
Mandaic |
 )
) )
) 
 )
) )
) )
) )
)_–_variant.svg)